

文科生到底是如何用中文玩转 Vibe Coding 的?这是范太太的亲历分享。
大家好,欢迎收听老范讲故事的 YouTube 频道。
Vibe Coding 并不一定需要写代码。范太太是一位英语老师,她终于决定自己上手 Vibe Coding 了。她做的事情是:在 Word 文档里用中文描述需求,输入 PDF 和 Word 文档,然后输出归纳整理后的 Word 文档。
这类繁琐的信息汇总、翻译、校对工作,绝对不是什么一键就可以搞定的事情。范太太也没有成为什么 Vibe Coding 大师,但是她觉得投入产出比已经为正了,确实节省了大量时间。
今天老范站在程序员的角度,和大家分享一下这个过程。对于程序员来说,我们可以借此学习文科生思考问题的方式,以后如果要为他们服务,应该如何下手。对于文科生来说,Vibe Coding 已经可以上手干活了,不需要学习编程,但有些思维方式还是要转变,有些坑也需要绕过。
今天的内容分成五部分

今天这个故事分成五段来讲:
- 先描述一下项目,到底干了一个什么活;
- 文科生开始 Vibe Coding 之路必须经历的 5 个坑;
- 从程序员的角度描述一下 AI 到底是怎么干活的;
- 当文科生都可以用自然语言,透过龙虾或者 Codex 这样的工具解决问题时,世界会变成什么样;
- 最后,不管你是工程师还是文科生,我们到底应该怎么办。
项目本身:到底在解决什么问题

大家可以想象这样一种任务:很多研究咨询机构都有一种很常见的工作,就是搜集各种报告,汇总到历年积累的完整数据报告里,再写出一份新的报告,说明过去几年所关注的行业或某个范围内发生了哪些事情,什么东西涨了,什么东西跌了,有什么趋势。
这些内容每年都要整理一次。国外很多机构也会发布相应报告,你需要把它们汇总在一起。在这个过程中,就涉及翻译。不管原始材料是什么语言,都需要翻译;总报告还需要不断补充和修订,去年是什么样,前年是什么样,今年的数据要填进去,有些五年前的数据可能还要删掉,只保留最近几年的内容。还需要让所有数据分门别类地补充到原来格式要求的正确位置上去。
这个事情非常烦。因为搜集来的不同来源报告,格式各不相同,写法也不同,甚至有些用词都不一样。有些喜欢用表格,有些喜欢写一大段描述;有些事无巨细,有些写得很简略。但最终目标报告必须是统一格式,而且最后可能还要拿这些数据去汇总,不能把数据加错了,关公战秦琼的事情是不能发生的。
这种汇总报告,通常是研究咨询机构自己出年鉴或者趋势分析报告的基础。找齐原始数据本身并没有那么难,因为大部分原始数据本来就是公开的。但是把这些数据按照复杂逻辑抽取、翻译、汇总,再进行校对,这个过程非常痛苦。
这也是研究和咨询服务之所以值钱的底层原因。普通人也可以拿到那些公开数据,但想把这些数据汇在一起形成结论,那就值钱了。谈笑风生的是大厨大师傅,但要做出一桌子菜,背后洗菜、配菜的人需要付出巨大劳动。
文科生开始 Vibe Coding 必须经历的 5 个坑

一开始先测试几轮,看看这东西到底行不行。结果效果并不好。并不是说你告诉 AI “去把这事干了”,它就噼里啪啦全干完了,没有那么聪明。AI 现在还做不到“上帝说要有光,于是就有了光”那个程度。
你说它做事了吗?确实做了,但是效果完全不可控。有些指令被执行了,有些被忽略了,有些结果本身就很混乱。很多人上来都会遇到这个问题,但不要着急。
第一个坑:先让 AI 复述需求,再开始执行
一定要先让 AI 读一遍需求,然后给出它的理解和不清楚的地方,再进行补充。这个非常重要。因为我们现在是用自然语言描述需求,而自然语言和程序语言最大的区别就在于:程序语言没有二义性,自然语言却可以有很多种理解方式。
人总是害怕 AI 搞不清楚,所以通常会写得很啰嗦,跟它讲半天。但 AI 到底理解没理解,其实你并不清楚。怎么办?很简单,让 AI 分析一下:你看看我说的这些事情你都明白了吗?或者你把这个事情拆一拆,到底有哪些我说清楚了,哪些没说清楚,你准备怎么干,跟我说一说。
很多领导带新人时也是这样。我跟你交代一个任务,你跟我讲讲我都说了什么,你打算怎么干,哪些事情你能干,哪些事情你干不了,需要回来问我。这就是正常的人与人交流过程。跟 AI 也是一样。
需求写完之后,你要让 AI 告诉你,哪些事情它明白了,清晰地列出 1、2、3、4、5,先干什么,后干什么,怎么校对。这个很重要。AI 一定要有标准,没有标准,它也不知道做成什么样才算合适。
同时,AI 通常还会在你的需求文档里找到说不清楚的地方,把它搞不明白的问题问出来。它会告诉你:有这几件事我搞不清楚,请你给我一个确定答案。
所以第一步一定要这么做。不要想着自己把需求文档写得很清楚了,直接让 AI 去干,这个事绝对不会有好下场。第一个坑就是:注意跟 AI 一起讨论需求,这是最重要的。
第二个坑:处理单元、定位和标识必须明确

虽然和 AI 说话使用的是自然语言,但处理的单元、定位和标识非常重要。
举个范太太遇到的实际问题。她要求把新一年的数据合并到过去总报告里,并且把发生变化的地方标成红色,方便校对。结果发现 AI 把整段整段都标红了。她觉得可能是自己没说清楚,以为 AI 把英文变成中文就当作“都不一样”了,所以整段标红。
于是她重新描述:如果只是翻译了,不用标;只有含义发生变化时才标红。结果还是整段都是红的。
后来跟 AI 讨论后终于明白了:你需要有“最小变更单位”的概念。到底以什么单位来判断是否发生变化,这件事必须说清楚。是按一句一句来判断,还是按别的方式?这个说清楚以后,AI 就给出了正确结果:一整段文字里,只把发生变化的部分标红,没有变化的部分保持原色,这样后期校对就方便多了。
所以,对于 AI 或程序来说,描述要求时一定要讲清楚:如何区分一个单元,怎么识别它,它的大小范围是什么,它具有什么特征,要对这个单元做什么操作。这样它才能清晰完成任务。
对于 AI 来说,做操作很容易,找到数据很难。AI 真正要干的活,是抽取、比较、翻译、校对和标注。当你把数据单元描述清楚以后,后面的事情它都很容易搞定,甚至还可以和另外一个你标注好的单元进行比较和合并。
AI 干活,或者说程序干活,基本就是这个格式:对什么东西做什么事情,或者对这两样东西做一个什么事情,然后放到哪里去。
第三个坑:很多默认操作并不默认,必须先说清楚
很多默认的事情其实不可控,必须先说清楚。
范太太的案例里,有一些分类去年存在,但今年没了。按道理,应该在今年的数据表格里把这个东西删掉,只保留今年存在的数据项目。对于人来说,特别是有经验的人,这就是默认操作,直接处理了就完了。
但 AI 不会这么做,特别是删数据这件事,它相对还是比较谨慎的。
最后只能补充描述:需要删除的数据不要直接删掉,而是用黄色背景重新标识出来,相当于拿记号笔画了一下,方便事后校对。因为如果直接删掉,你根本不知道原来这里有没有数据,也没法校对。
人干这个活,可能看到就直接删了;但 AI 干活相当于是你有了一个助手,它干完以后你还得再看一遍,所以不能让它直接把数删了。
做了这样的描述以后,AI 就把这种默认处理情况处理清楚了。有时候你觉得 AI 很笨,其实原因并不是它真笨,而是很多人类约定俗成、不用说也知道怎么办的事情,AI 并不知道。你必须明确告诉它。AI 也可以去猜,但那就完全不可控了。
第四个坑:复杂任务一定要拆分
对任务进行分拆非常重要。很多步骤如果让 AI 一把搞定,得到的结果是无法验证和使用的。但 AI 在中间某一步的结果可能是有效的,所以把复杂任务分拆就变得非常重要。
那应该怎么拆?横着拆还是竖着拆?其实不需要去思考 AI 第一步干什么、第二步干什么,在哪一步的结果上出下一步,也不用去搞清楚哪部分重要、哪部分不重要。这些都没关系。
分拆任务的唯一标准是:这一部分能不能独立验收,能不能确认价值。如果可以,就把它拆出来。
你可以让 AI 先把这一块搞定,搞定以后我们可以校验这一块。而且这一块原来特别麻烦,现在 AI 做完以后变得非常简单,人只要确认一遍就行。那它就可以单独成为一块任务。哪怕后面其他步骤出了问题,留下来的这一部分仍然是可用的。这是 AI 处理任务里非常关键的一点。
第五个坑:不要指望 AI 完全搞定,或一次搞定

不要抱着“完全由 AI 搞定”或者“一次搞定”的想法。这是很多人使用 AI 处理问题时最大的坑。
有些步骤 AI 可以搞定,因为它很擅长。根据前面做的任务分拆,就可以得到很多可验证的子任务。剩下的部分,你跟它描述半天,有时候还不如自己干。那干脆就直接上手,因为我们最终要的是结果,不是一个什么都能处理的 AI 工具。
所以一定要想清楚:什么事 AI 干着方便,结果基本可用;什么事人干着方便,只要稍微动动手就能搞定。这个一定要灵活调整。不要惦记着让 AI 把所有事情都搞定,或者一次把所有事情搞定。拆开以后,适合它干的它干,不适合它干的自己干。
这其实有点像带人。比如今天带了一个新学徒,有些事你指挥他干或者教他干,下次他可能还能干出来,而且还能给你省不少事;但有些事,真不如自己上手,三下五除二就搞定。所以我们最终要的是结果,不是别的东西。这一点一定要搞清楚。
这就是文科生使用 AI 过程中必须注意的 5 个点,也可以说是必须绕开的 5 个坑。
实际使用中暴露出的其他问题
当然,还有一些其他问题也在逐渐发现。这里面我跟我太太也有一点小争执。
争执一:坚持使用 Word 是否合适
第一个争执,是她坚持用 Word。Word 是一种非常庞大、功能非常齐全的标记性语言。虽然现在这种标记性语言已经开放出来了,但真正有用的信息,也就是我们写进去的文字,占比实在太小。
使用 Word,会给 AI 处理需求带来巨大的不确定性,因为里面有大量格式说明的内容,这些也要占 token,而且可能会影响结果。
不过目前来看问题不大,因为 AI 上来会先把 Word 拆成 Markdown 或纯文本,再去处理,而不是直接去管那些格式信息。
争执二:文件名和目录管理必须规范
第二个争执,是文件名和目录名。她比较喜欢在一个文件里改来改去,但在我看来不行,必须拆到不同文件和目录里去工作。改完以后,就起一个新文件名,哪怕在文件名后面加上日期都行,千万不要还用原来那个。
其实程序员平时并不是这么干活的。程序员通常是在同一个文件上改来改去,但我们处理的是纯文本,没有格式信息,所以可以用版本控制工具,甚至做代码合并,把不同版本合在一起。
但她用的是 Word 文档,里面有大量格式信息,会干扰文本内容,很难对这种文档做版本控制、差异比较和合并。
所以我强制要求她每做一件事情都新建目录、新起文件名。至少到目前为止,这样做得到了一个可接受的结果。因为如果不这么做,你没法和 AI 来回配合,不知道哪些是它改的,哪些是你改的,也搞不清哪些是可验收的结果,哪些是中间结果。不断起新文件名,可以解决这个问题。
从程序员角度看:AI 到底是怎么干活的
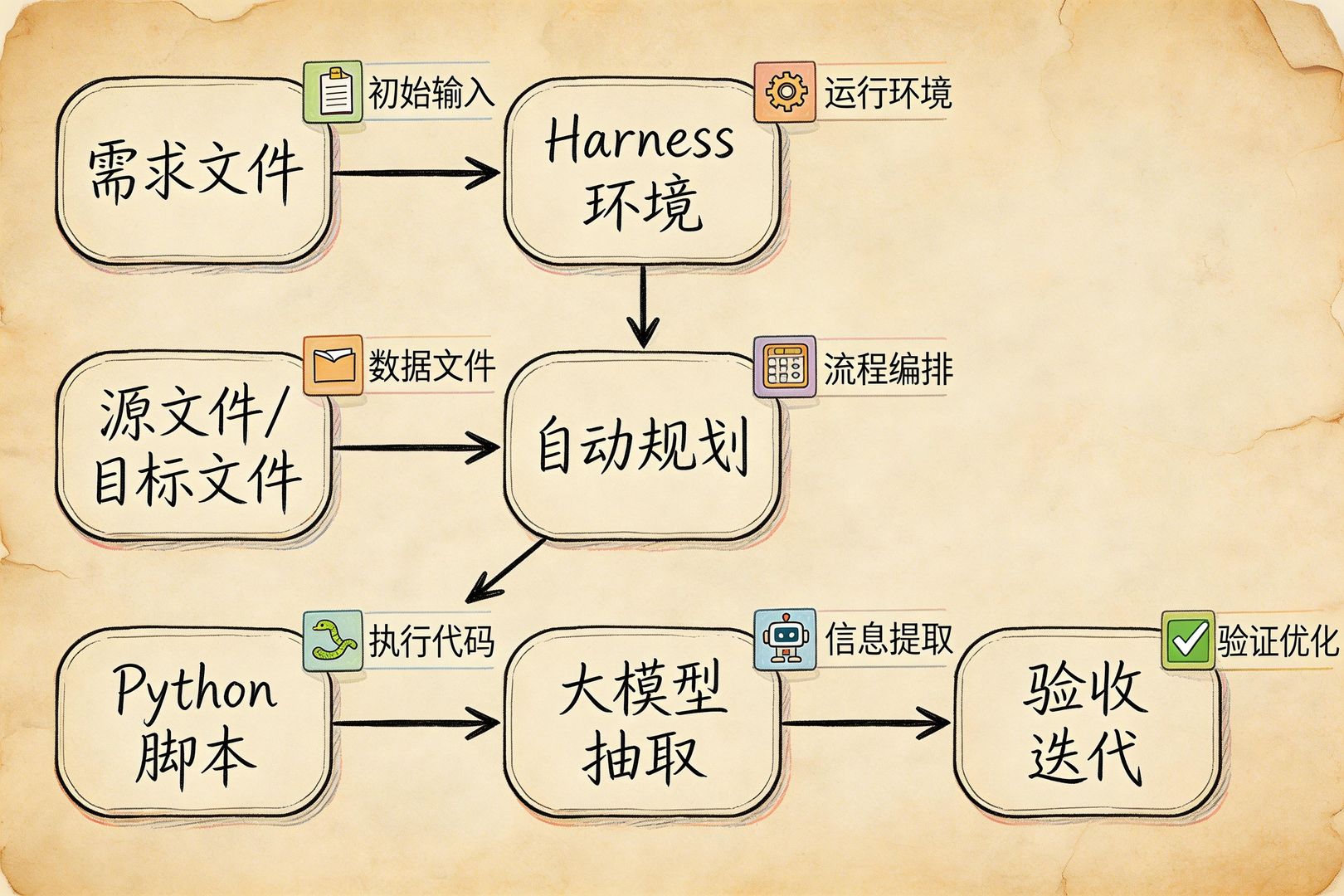
既然前面讲了,文科生只要在 Word 文档里写中文描述,它就能把事情做出来,而且做出的结果确实有用、有价值,那它到底是怎么干的?
1. 先进入 Harness 环境
现在这就是典型的 Harness 环境。Codex、OpenCode、Antigravity、Claude Code,或者龙虾 OpenClaw,都属于这种 Harness 环境,都可以干类似的活。当然,这里头最好用的应该是 Claude Code,只是老范没有 Claude Code 账号,所以用的是 Codex。
2. 先找到过程描述文件
系统拿到指令以后,会先找到指定的过程描述文件,也就是我告诉它应该按照哪个文件里的描述去干活。
其实编程也是类似的过程,只不过我们会有约定俗成的入口文件,比如 main,编译器会从那里开始,然后决定引用什么东西、一步一步怎么做。现在既然是 Word 文档,那我们就需要明确告诉系统:请按照哪个文件名里的描述去干活。
3. 再寻找源文件和目标文件
然后 AI 会去寻找源文件和目标文件,也就是你到底要处理哪个文件,处理完以后生成什么结果。
4. 自动规划执行步骤
接着 AI 会自己做规划,不管是 Codex 还是别的工具,都会自己规划:第一步干什么,第二步干什么。
5. 自动编写 Python 代码
规划完以后,它会自动去编写 Python 代码。这部分我们不用管。到现在为止,我也没有看过任何一行 Python 代码,甚至我自己也不太会 Python,所以这并不重要。
6. 把确定性任务交给程序执行
接下来,AI 会把确定性的任务扔给 Python 去跑。比如从 Word 或 PDF 里抽取文本,做简单比对,判断这个和那个是不是相等,进行数据填写,把目标填到哪里去,以及文档格式化。
所谓文档格式化,就是在 Word 文档里除了文字之外,再加一些标记,比如这里是红色、那里是几号字。这些都属于确定性任务。
7. 把不确定任务交给大模型处理
还有一些不太确定的任务,需要调用外部模型来做。比如非结构化数据的信息抽取。我写了一大段文字,里面说某年某月某日,某公司投资了谁多少钱,占股多少,这就属于非结构化数据。
我们可以给大语言模型一个指令,让它抽取时间、公司名、甲方、乙方、投资金额、持股比例、估值等信息。这类信息抽取就需要大模型来完成。
还有翻译,也可以由大模型来做。翻译当然也可以通过远程 API 或专门翻译接口搞定,但通过大模型也能完成。
8. 根据验收结果反复迭代
做完这些以后,AI 会根据前面讨论过的验收结果,对输出进行验收。如果发现不对,它会重新编写 Python 代码,再干一遍。它也是分步骤的。如果哪一步做对了,就保留对的部分,把不对的步骤继续往下做。这就是整个运作过程。
当然,这个过程充满了很多不确定性。比如我们描述了数据,但它没有找到,或者它找到了一些数据,却和我们的描述不完全一致,只是有点像。
这个时候它就会尝试:是不是可以这样试试,那样试试?它在读源文件和目标文件时,如果发现原始文件里有一堆跟你的描述很像的数据,就会考虑:我是不是可以写一个信息抽取模块把它们抽出来?还是说我可以写一个 Python 代码,把它们提取出来填到另一个地方去?
它就是不停地做这样的事情,把尽可能确定、可验证的事情做到它确认的最好结果,然后告诉你:这块我做完了。做完以后,它有时还会问你,我可以进一步再验证一次,要不要我去做?一般我们会说,你再验证一次吧,再进行一次手工验证。它就会按照要求再把目标文档验证一次。这就是 AI 真正干这个活的过程。
当文科生都能用自然语言解决问题,世界会怎样

文科生不需要会写代码,但必须有逻辑
第一点,文科生不要害怕使用 Vibe Coding 工具。不需要懂代码,但逻辑依然非常重要。你自己都描述不清楚的问题,AI 也搞不定。如果实在描述不清楚怎么办?可以跟 AI 讨论,它能够帮助你把逻辑梳理清楚。
AI 提效意味着部分岗位会被替代
但也有一个很现实的结果:大裁员就在路上。范太太通过 AI 完成一部分工作,再结合她自己手工处理,相当于半自动完成整个流程。跟原来纯手工相比,大概能够节省 60% 到 70% 的时间。
那些专业技能要求不高,但非常机械、枯燥的工作,一旦交给 AI,从体感上就会舒服很多,因为这部分工作真的很烦,把它交给 AI 还是很开心的。
很多工作的本质,是在非结构化与结构化之间来回转换
以前很多工作,实际上就是把各种非结构化数据结构化地处理,再以格式化的非结构化形态输出。这个说法有点绕,意思是:最早的数据其实在数据库里,都是结构化数据,一行一行,各种关系都很清楚;但当我们把它写成报告时,会加很多格式,比如字大字小、各种字体、换颜色、加图标,这个过程叫格式化。
可格式化完成的 PDF 报告,又重新变成了非结构化数据,因为很多内容变成了一大段一大段文字,有些即使是表格,也没有足够清晰的说明和约束,实际上依然是非结构化数据。
真正的结构化数据,是有非常清晰的数据字典和数据约束的。这些数据被公开时,公开出来的是花里胡哨的发行版,也就是格式化好的非结构化结果。而研究咨询和数据机构的价值,就在于他们手里有结构化数据,可以方便地研究、辅助决策,并再次输出。
比如找四大或者各种咨询公司,他们不会把后台数据库开给你,真正的结构化数据永远不会给你,给你的都是一份一份报告。你要是想把这些报告重新塞回数据库里再去应用,难度非常大。
刚才讲的整个任务过程,本质上就是把一大堆公开的、非结构化的、格式化好的、花里胡哨的报告,重新塞回数据库里,再生成一份新报告。以前这些事都要靠人工完成,很多研究机构也是不断拿别人报告回来,往自己数据库里填。
你说能不能专门编写软件来做?当然可以,但成本非常高,而且这种报告可能一年才用一回,最后不划算,还不如找个人吭哧吭哧去做。现在 AI 不能说彻底搞定了这件事,但绝对可以极大提效。如果没有新的业务和收入进来,那就只能裁员了,这没什么办法。
更积极的一面:更多人能用上更完整的数据
说点正面的。既然生产效率提高了,总应该有好处,不能光带来裁员。
正面的地方在于:我们每个人在做决策时,都可以使用更完整、更新、更准确、更大范围的数据了。那这东西有用吗?能赚钱吗?数据就是财富,数据就是权力。
当每个人、每个机构都能获得原来难以企及的数据之后,就会做出更正确的决策,或者决策效率大幅提升。这样就会有更多新生意出现,原来没法做的,现在可以做了。这才是真正正面的部分。
所以,让我们动起来吧。
最后建议:程序员和文科生分别该怎么办

给程序员的建议
对于程序员来说,我通过观察文科生用 Vibe Coding 处理问题的过程,已经能更清楚地知道:以后如果有人想用类似方式处理问题,他们可能会遇到哪些问题,以及这些问题应该如何解决。这对我来说是一个帮助。
给文科生的建议
对于文科生来说,记住这 5 点非常重要。我们把顺序稍微调一下。
- 放弃让 AI 一次搞定、一键搞定所有问题的幻想,这不现实。
- 和 AI 讨论需求和处理步骤。因为我们使用的是自然语言,尤其是文科生的自然语言,往往会更啰嗦一些。让 AI 帮你梳理清楚,把你没说清楚的地方列出来。
- 向 AI 描述如何识别和获取目标数据的特征和范围,这是最重要的。AI 能找到需要处理的数据,至于怎么处理都相对简单;关键是它怎么识别出这个数据。你一定要把这块讲得非常清楚。
- 把各种默认状态都明确描述出来。很多事情是人一看就知道怎么办的,AI 没那么聪明。
- 把完整任务按照可验收的价值点进行分拆。把 AI 擅长的事情交给 AI,把 AI 不擅长的事情自己上手,这样才是最高效的方式。
如果你已经订阅了 OpenAI 或者 Anthropic 的各种套餐,抓紧把 Vibe Coding 工具跑起来;家里已经有龙虾的,或者准备装龙虾的,也别让它闲着。
好,这就是今天的故事。感谢大家收听。请帮忙点赞、点小铃铛、参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
背景图片
