

最新编程跑分:大模型全军覆灭,但真正可怕的不是 0%
大家好,欢迎收听老范讲故事的 YouTube 频道。
这两天,AI 编程圈出了一个新的跑分,叫做 ProgramBench。这个测试非常狠:它不是让 AI 去改一个 bug,也不是让 AI 补一个函数,也不是让 AI 在现有项目里加一个小功能。
它直接把题目做成这样:给你一个已经编译好的可执行文件,再给你一份使用文档。你根据文档和可执行文件去测试:应该输入什么、输错以后该怎么报错。源码什么都不给,然后让 AI 自己规划,写出完整的程序。
这已经是一个完整的软件工程了。以前很多人都说,AI 可以写一部分代码,可以补个 bug,但你给它一个完整项目,它写不出来。老范自己做直播的时候,很多程序员也会说:
你看看,你让它做一个这个,你让它做一个那个,它做得出来吗?
原来确实做不出来,这一次测试也说明它做不出来。但是事情并没有大家想象得那么简单。
ProgramBench 的结果:9 个模型,全员 0%

这一次一共用了 9 个模型做测试,全员通过是 0。
测试大概选了 200 多个软件,都是大家比较熟悉的各种底层开源软件,而且给到模型的是已经编译好的版本。每一个软件都有很多测试项,比如输入这个参数应该怎样,输入那个参数应该怎样,错误信息应该怎么处理。整体加起来有几千个测试项,论文中给出的总测试项是 248,853 个。
9 个模型测完以后,没有任何一个软件的所有功能可以全部通过。所以这一次就是全军覆没。
参与测试的模型包括 Claude、GPT、Gemini 系列,其中有 Claude Opus、Claude Sonnet,GPT 有 GPT 5.4、GPT 5.4 Mini,Gemini 有 Gemini 3.1、3.0 Flash Pro 等,合计 9 个。
很多人看完以后的第一反应可能是:程序员这饭碗保住了,AI 吹了半天牛,最后还是没法完成完整的软件工程吧?
这句话在测试结果公布的这个点上是对的,但也只对了一半。因为我看完以后,真正让我冷汗直流的不是那个 0%,而是另外一件事:这个 Benchmark 已经把下一代 AI Coding Agent 要攻克的目标定义得非常清楚了——AI 要完成完整的软件。
真正可怕的是:目标已经被定义出来了
你不要给它选型,不要告诉它要用 C、JavaScript 还是 Python。你就说:我有一个应用,这头输入什么,那头输出什么,你给我再做一个。
这有点像修车。原来是某个部件坏了,我要等原厂配件,非原厂配件不好。以后可能变成:我缺一个配件,你给我重做一个。这个配件长这样,输入是这些,输出是那些,你给我做出来就完了。

一旦目标被定义出来,接下来就不是会不会的问题,而是什么时候的问题。甭管是美国人做 AI,还是中国人做 AI,大家都喜欢干一件事:刷题。
原来没有一套题来规定未来要向哪个方向发展,大家就不知道该刷谁。当一套题已经明确未来方向,剩下的事不就是刷吗?所以 ProgramBench 出来以后,所有做 AI Agent、做软件的厂商,方向就已经明确了:奔着这个方向刷就完了。
从 SWE-Bench 到 ProgramBench
ProgramBench 是由 SWE-Bench 这个团队做的。SWE-Bench 其实已经是 AI 编程领域里比较难的测试了。
在 AI 编程领域,最早的测试方式是:我给你出题,让你做一个排序、一个算法,做完以后验证对不对。到 SWE-Bench 的时候,他们做了一件更狠的事:给你一个 GitHub 仓库,上面有一些 bug,也有人提 issue,说这里有问题、那里有问题。AI 要自己把代码拉下来,读清楚问题,提交补丁,把问题解决掉,再看通过情况。
这已经开始解决现实问题了。
现在的大模型跑 SWE-Bench,很多已经可以跑到 70 多分,也就是 70% 多的问题都可以自动搞定。而且这些大模型在 SWE-Bench 上已经有点拉不开差距了。即使是国内的大模型,比如 DeepSeek、千问、Kimi,在这块都已经跑得非常靠前。甚至有些模型还可以跟 Claude Opus 4.7 稍微掰掰手腕。
因为在大模型领域里,最容易提升的就是编程。编程比较确定:要求是什么,输入是什么,输出是什么,中间可能出现什么问题,应该怎么解决,这些都相对明确。大模型可以一遍遍刷,不对就再刷一次。而且它不光知道哪个是对、哪个是错,还知道什么样更好。所以大模型在编程能力上提升得非常快。
当一个 Benchmark 已经没法再区分大模型能力的时候,怎么办?那就出更难的题。就像考试时所有人都考 100 分了,老师就再出一套更难的题。ProgramBench 就是在这个背景下出现的。

ProgramBench 到底怎么考
这一次不是修 bug。修 bug 仍然是在一个已经完成的项目里工作:项目用什么软件、什么技术栈、什么编程语言、什么目录结构、什么架构,人家都写好了,只是里面有一些 bug,你进去修就行。
ProgramBench 没有这些,只有一个黑箱子。
什么叫黑箱子?就是我知道输入什么、输出什么,但不知道里面怎么处理。等于我给你一个黑箱子,剩下的你要把箱子里的东西做出来。
ProgramBench 的论文名字叫“大语言模型能不能从零开始重建一个软件”。它设计得非常干净,也非常狠。
研究团队给模型的东西只有两类:
- 第一类:已经编译好的可执行文件。
- 第二类:这个程序的使用文档。
模型可以运行这个可执行文件,比如加一个 -a、加一个 -b,输入一个文件名,再输入其他参数,观察应该出现什么结果。文档里会写这个软件是什么,有哪些参数。
这里测试的都不是有图形界面的东西,而是 text in, text out,基本属于 Unix 平台的规范:输入是文本,输出也是文本,跟图形界面关系不大。
研究团队不会给:
- 源代码;
- 测试用例 test case;
- 项目结构;
- 技术栈;
- 应用内部使用了什么函数。
模型要自己运行程序,观察输入输出行为,然后推理它有哪些命令行参数、如何处理边界情况、出错以后怎么办。
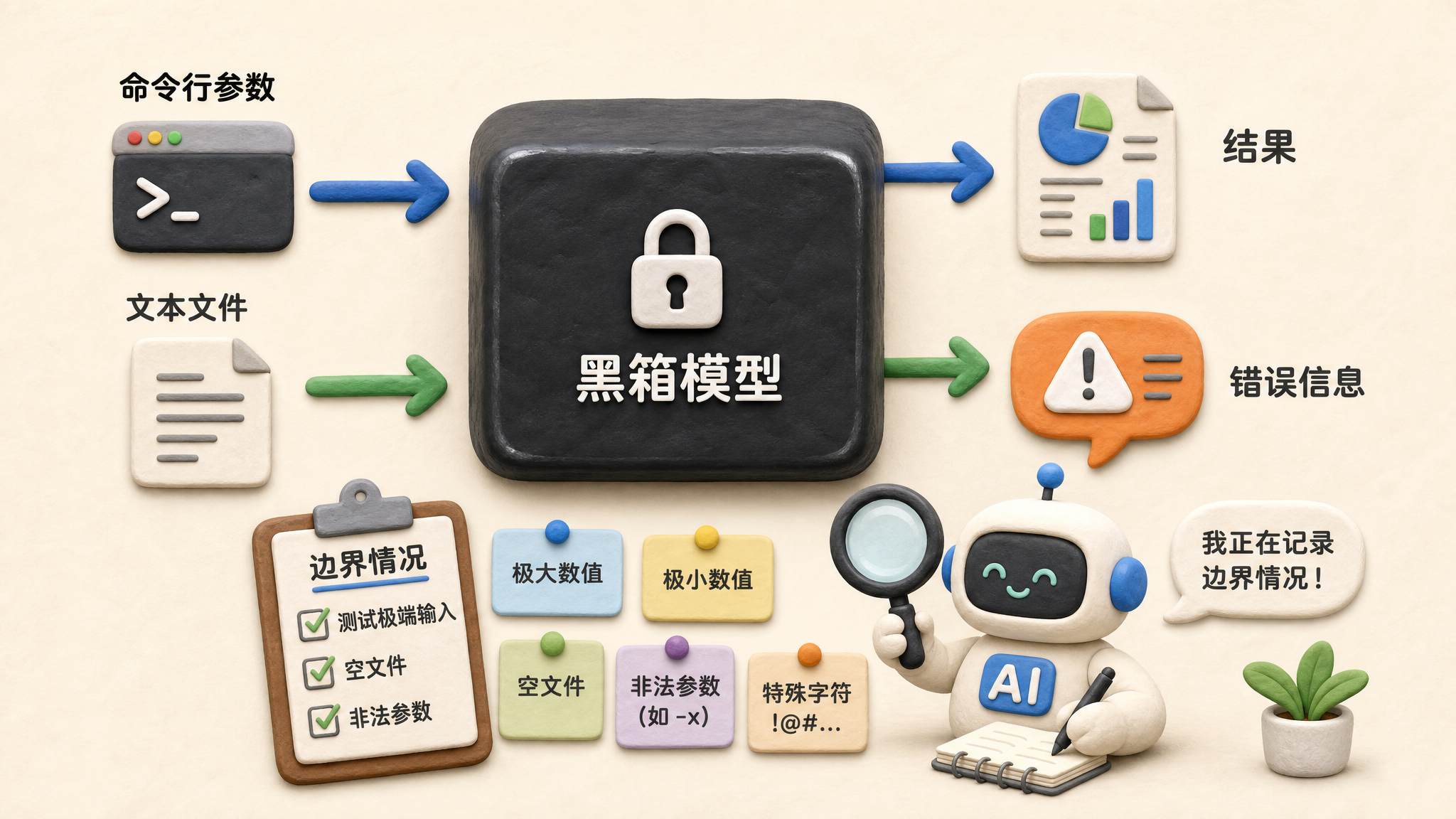
比如应该输入三个参数,结果只输入了两个,程序应该怎么处理?应该输入大于 0 的数,结果输入了小于 0 的数,应该怎么办?出异常时应该输出什么错误信息?这些都属于边界情况。
程序内部大概有什么样的数据结构,也可以通过行为观察。比如一个执行文件收到一些数据后,会在目录里创建数据文件,把输入信息存进去。模型可以观察这些行为,再自己决定用 Python、C、Rust 还是 Go 来重写,整个项目应该如何组织。
所以 ProgramBench 跟 SWE-Bench 已经不是同一个层次了。SWE-Bench 相当于修车:车还在,坏了一个零部件,我把它修好。ProgramBench 则是:我想要一辆车,它要具备某些特性,比如看到红灯会停、看到行人会按喇叭,剩下什么都没有,你去造吧。
任务规模:真实软件,不是玩具项目
这次是 200 个任务,每个任务有一堆测试,总共 248,853 个测试项。任务不是玩具项目,而是真实软件项目。
比如:
- 压缩工具:Zstd、LZ4、Brotli;
- 语言编译器或解释器:PHP、Lua、TinyCC;
- 数据库:SQLite、DuckDB;
- 媒体处理工具:FFmpeg。
其中最大的项目是 FFmpeg,很多人做视频编解码都会用到。这个项目有 270 万行代码,也被放进测试里,让模型去重建。

当然,这些软件并不全都像 FFmpeg 这样大。很多项目比较小,平均代码中位数是 8,635 行,能够到 270 万行的只有 FFmpeg 一个。
这次测试考验的是:AI 有没有能力做软件架构、系统推理和长期工程设计。
成绩细节:Claude 稍微领先,但也只是“接近完成”
成绩是全员 0%,真的是全军覆没。即使是最简单的应用,上最好的模型 Claude Opus 4.7,也没有通过全部测试项。
当然,在这批模型里,Claude 还是稍微强一些。
测试里有一个指标叫“接近完成”:如果所有测试项里大概有 95% 都通过了,就算接近完成。按这个指标计算:
- Claude Opus 4.7:3%;
- Claude Opus 4.6:2.5%;
- Claude Sonnet 4.6:1%;
- GPT 5.4:0;
- Gemini 3.1 Pro:0。
也就是说,用 Claude 还有可能做出一个差不太多的版本,但用 GPT 和 Gemini,连 95% 都达不到。从这一点看,Claude Opus 4.7 还是稍微领先一些。
如果有人好奇:它到底是把最简单的项目完成了 95%,还是把 FFmpeg 这样最难的项目完成了 95%?答案和大家想象差不多:越难、越大的项目越难完成,完成度越低。能够完成 95% 以上的,一定是相对简单的项目。
这次测的是模型能力,不是最强 Coding Agent 能力
还有一个重要细节:这次测试并没有使用 Claude Code,也没有使用 Codex,而是使用了一个比较轻量级的开发 AI Agent,叫 mini-SWE-agent。所有大模型都是在统一的 Agent 上跑出来的。
如果现在让 Claude Code 或者 Codex 去跑这些测试,完成度可能会提高一些。所以今天讲的是测试中的大模型能力,还不是最强 Coding Agent 的能力。
现在想让 AI 完成完整项目,很多时候提升可能不在大模型本身,而是在 Coding Agent 上。
所以 ProgramBench 真正测出来的是:今天的模型加上一个很轻量级的 Agent,还没法完成完整软件的重建。这并不等于未来上 Claude Code、Codex 这种更强的 Coding Agent 以后就一定做不出来。
一个有趣细节:AI 也在千方百计“作弊”
在这个测试里,有一点很有意思:测试时命令这些 AI 不允许作弊,也就是不允许抄源代码。否则如果能拿到源代码再去做,就失去了考核目的。
但是 AI 都在千方百计地作弊。
它们的第一种处理方式,是先上 GitHub 找源代码,然后去改。发现这事不行,不能这么干。
第二种方式,是使用包管理,想办法把包含源代码的包拉回来,再研究怎么做。这个也不允许。
第三种方式,是去电脑里的包缓存目录翻。Unix、Linux 或 macOS 会有很多软件包,拉下来以后会缓存在某个目录里,以便后续更新和维护。模型就去这些目录里找源代码。
后来没办法,研究团队说:断网吧。

所以这一次测试是在断网环境下进行的。这里的断网不是说不能连接 OpenAI、Anthropic 的服务器,而是说没有联网工具,不能使用搜索工具和 Web 工具,只能连接模型自己的服务器。这样才得到了一个相对公允的测试结果。
如果允许这些大模型联网,它们应该可以更好地复刻这些软件。
为什么 0% 反而让人冷汗直流
讲到这里,为什么老范看了这个测试结果以后会冷汗直流?这不是标题党。
因为这个 0% 并不是证明 AI 很弱,而是说明一个新的方向已经找到了。ProgramBench 表面上的结论是:今天的大模型还无法完成完整的软件工程项目。但更深一层的结论是:完整软件工程第一次被 Benchmark 化了。
也就是说,这件事已经被做成题了。以后大家只管刷题就完了。这个才是真正让人紧张的地方。
在 AI 发展里,一个任务一旦被明确地定义下来,可以稳定评测、稳定排名,就会进入工业化刷题流程。所有 AI 厂商、AI Agent 厂商、开发工具厂商,都会拼命刷这个题。如果谁刷的名次很高,就可能拿到融资,这背后有经济利益刺激。
最早大家说 AI 到底会不会写代码,于是有了 HumanEval。很快这个测试就被刷漏了,所有模型都能得到很高分,拉不开档次。
再往后 SWE-Bench 出来了,说不要只做写死的题,去解决现实问题,到 GitHub 上改 bug。结果现在这个也快搞定了,又拉不开档次。
那干脆做完整的软件吧,ProgramBench 就出来了。
这意味着下一个阶段,所有模型公司、Agent 公司、开发者工具,都知道应该向哪里使劲了。要攻克 ProgramBench,至少需要这些能力:
- 长期规划;
- 行为探索;
- 系统抽象;
- 自动测试;
- 多轮纠错;
- 记忆管理;
- 工具链协作。
你会发现,这正好是现在 AI Coding Agent 行业正在卷的方向。所有这些关键词最后都会汇聚到一个目标上:让 AI 从写代码片段,进化到维护、重建完整的软件系统。

所以,0% 只能说明今天这些模型还做不到从头开始写软件。真正让人紧张的是:路线图已经清楚了,测试也已经放好了,大家上吧。
更可怕的事:AI 写的软件,可能根本不是给人读的
当然,这还不是最可怕的。最可怕的是:AI 写出来的软件,可能根本就没有考虑过需要让人读。
ProgramBench 里有一个很奇特的发现,比 0% 更值得软件工程师认真思考。论文提到,模型倾向于生成单个文件,写特别长的函数。公开材料里的对比很有冲击力:模型生成的代码文件很少,目录层级很浅,函数数量更少,但单个函数特别长,代码总量比原项目少很多。
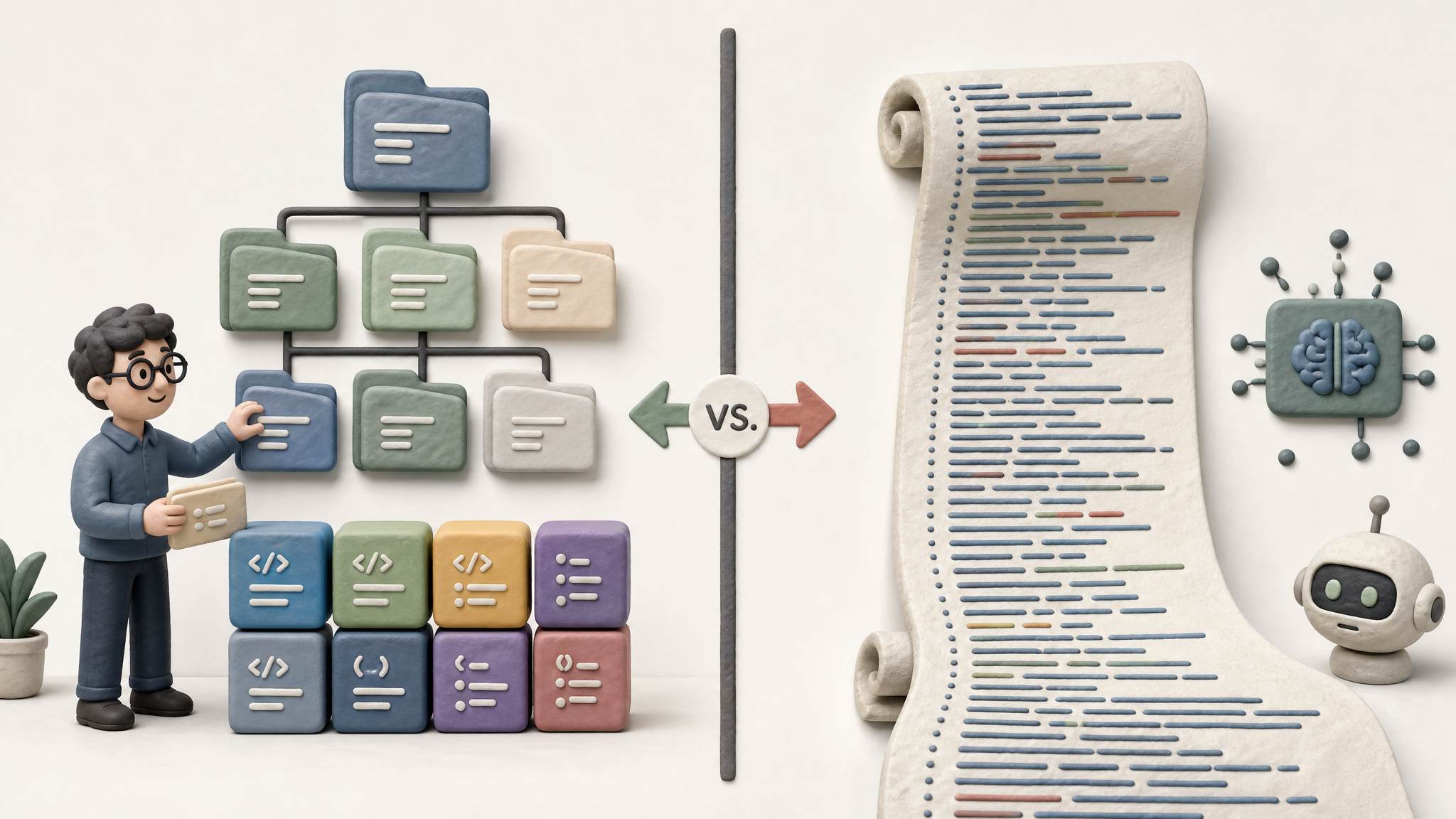
从人类软件工程的角度看,这一定是个很烂的项目。如果哪个程序员把程序写成这样,肯定会被劈头盖脸骂一顿。因为这种代码别人没法维护,他自己以后也没法维护,属于软件工程上完全不合格的代码。
但 AI 就给你写出来了。
很多程序员听到这个结论以后可能会觉得开心:AI 只能写这种代码,它不懂软件工程。千万别这么想。我们为什么要做复杂的软件工程?主要有两个目的。
第一,代码复用
代码写完以后,下次还要接着用。原因有两个:
- 代码写起来很贵,复用以后可以降低软件生产成本;
- 一个代码被复用后,只要改这个代码,所有相关地方都可以一起改,不需要每个地方单独改一遍。
第二,团队协作
一个项目通常需要很多人一起协作,因为一个人写不下来。而且人的记忆力是有限的。
我们经常批评 AI 的上下文很短,但 AI 有 100 万 token 的上下文,人却没有办法记住 100 万字的东西,并且精准告诉你第几行第几列写了什么。人没有这个能力,所以我们必须把函数写短,把项目规划好,把不同东西放到不同目录里。
把每个文件写短还有一个好处:修改其中一部分时,其他代码在其他文件里,跟它没关系,可以进行错误隔离。版本升级时,也只需要考虑修改过的文件,其他文件不需要重新考虑。它们的编译结果可以继续用,甚至测试结果都不用改。
这些都是人类维护软件工程时的考虑。
但 AI 可能不需要这些软件工程规范
现在对 AI 来说,很多问题可能不存在。
AI 不需要像人类一样代码重用,也不一定需要知道每个代码里有什么,到时候搜索就完了。需要修改时,它可以把所有相关东西都改掉。下次再烧点 token,重写一遍。它没有那么强的软件重用需求。
从团队协作角度看,它也不一定需要跟人协作。它可以跟 AI 协作。它有 100 万 token 的上下文,也可以有一套矢量数据库进行代码检索,把大量代码一把塞进去,然后精准快速定位哪一段在干什么。
所以我们认为在软件工程上完全不合格的代码,对于它来说反而很方便。
举一个最简单的例子。人写代码时,经常要求变量名、函数名要起得特别小心,稍微长一点,把函数具体干什么写清楚。为什么?因为下一个人要读。你不能写一个函数名叫 a,别人完全不知道它是干什么的。
但是对 AI 来说,函数名写长和写短有什么区别?只有一个区别:写长了多烧几个 token。除此之外没有本质区别。
如果代码根本不需要人看,它就不需要按照人类规范写函数名。它可以写短一点,省几个 token。AI 可以写出代码来,效率很高,执行得也很好,而且不需要进行人类理解上的区隔。它可以把整个东西都改掉,然后把所有测试跑一遍就完事。
最让人害怕的是,以后 AI 写代码,人类可能插不上手了。
最早 AI 叫副驾驶,叫 Copilot。我写完代码,它帮我改。后来 AI 在我写好的 GitHub 仓库里改 bug,它改完的 bug,我还是可以看明白,还可以接着弄。
但是 ProgramBench 之后,它写的代码我可能看不明白了。虽然语法还是编程语言,我还能一行一行读,但如果你给我一个 5 万行的代码,我从上到下看就会看傻。
人类需要对代码进行抽象、继承、架构设计。AI 可能不需要,只要代码能跑就完了。
机器真正执行代码的时候,本来就不关心变量名起得多好。人写的源代码里有复杂的软件工程设计,但很多东西在编译和优化时都会被扔掉。机器只需要知道变量里的数据存在哪个地址,不需要知道它叫什么长长的名字。
所以 AI 虽然现在还没有开始直接用二进制机器码写程序,但它现在写出来的程序,人已经很难再看了。我记得马斯克前面好像说过,以后 AI 写代码可能就直接写机器代码,直接写编译过的结果,不需要写那种由人参与、由人维护的代码。可能马斯克在这件事上更高瞻远瞩一些。
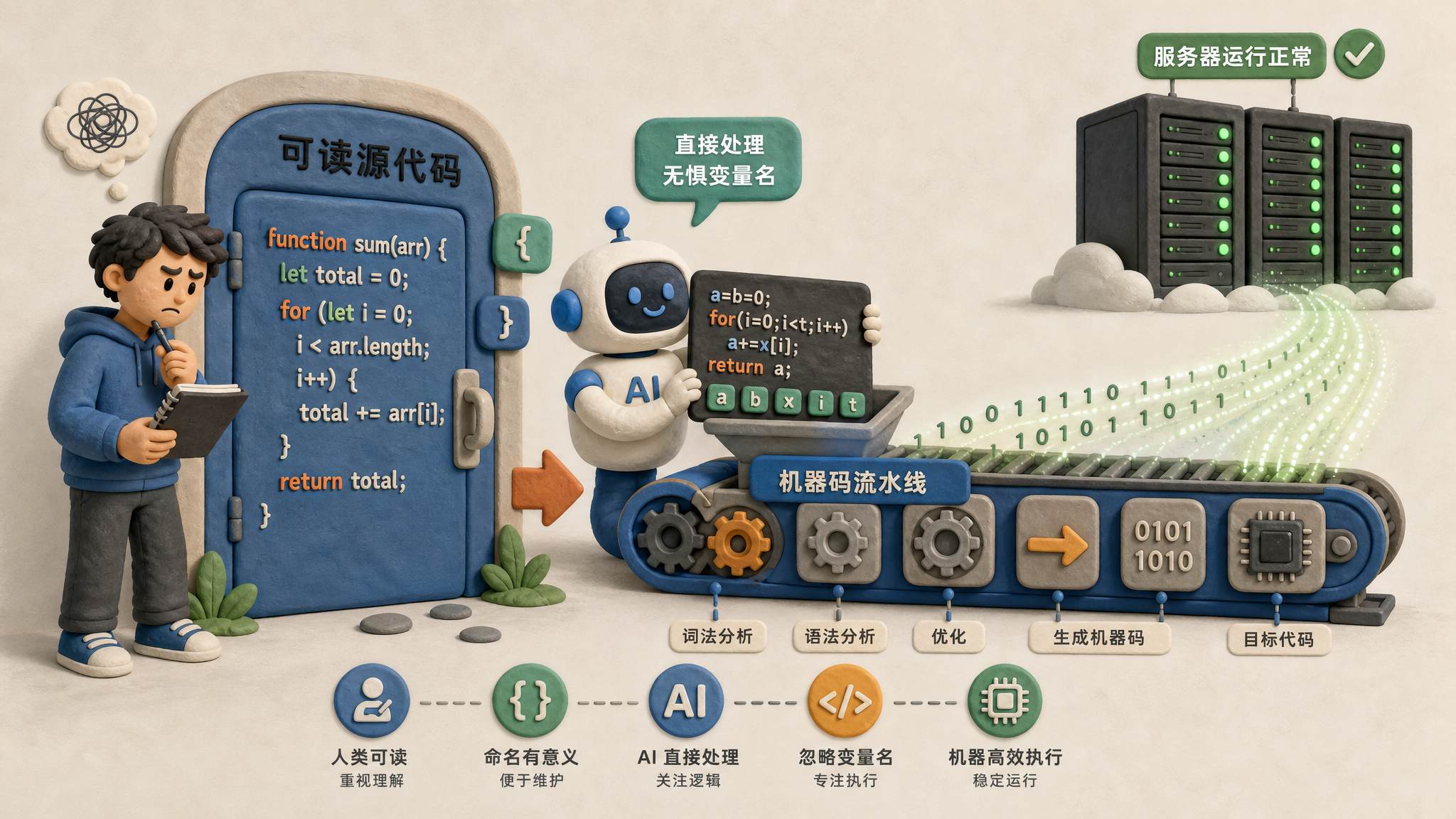
巨型脚本可能不是屎山,而是一种新生产方式
ProgramBench 里最让我害怕的一点,还不是 AI 找到了正确方向、要开始做完整软件了,而是:今天 AI 写出来的巨大一坨脚本,可能不是屎山。
这种巨型脚本可能代表一种新的软件生产方式:
- 它不优雅,但是便宜;
- 它不适合人类阅读,但是适合 AI 重写;
- 它不服务于团队协作,但是服务于自动化迭代。
还有一个很重要的点:这次作为题目的 200 个项目,都是 Linux、macOS、Unix 里很底层的模块,比如压缩、开发、媒体处理。程序员不可能每个人都从头从零做这些东西。
但现在 AI 开始测试:怎么把最底层的地基重建一遍。一旦 AI 可以快速重建整个地基,人类可能就逐渐不会写程序了。甚至它重写以后发现,不需要遵守原来的协议,自己内部调用就行;自己写一个很小的模块放进去就完事。那人类可能会离现实编程越来越远。

这对程序员、创业者和投资人意味着什么
对程序员:饭碗暂时保住了,但工作内容会继续上移
今天的大模型还做不到完整软件系统的重建,这说明软件工程仍然很难。特别是架构设计、需求澄清、长期维护、系统安全、团队协作、业务理解,这些能力仍然是人类的优势。
但是不要把 0% 理解成完全安全。因为 AI 最擅长的就是沿着 Benchmark 快速迭代。
程序员真正要做的,不是证明 AI 不行。很多人特别喜欢干这个事,但这对你没有任何好处。
程序员真正要做的,是把自己从代码执行者升级成:
- 需求定义者;
- 系统验收者;
- 工具链组织者;
- 质量负责人;
- 业务和技术之间的翻译者。
未来最危险的程序员,不是不会写代码的人,而是只会写代码,却不会定义问题、验证结果、控制风险的人。这些人可能就要失业了。
对 AI 创业者和投资人:新的 Benchmark 已经来了
对于 AI 创业者来说,Benchmark 已经来了,卷吧,上去刷。
对于投资人来说,谁刷得好就投谁,这就是未来的方向,而且非常明确。
旧的榜单依然有效,SWE-Bench 还是有效的。它现在并没有被刷到 100%,大概是 70% 多,还可以继续往上刷,只是已经没有特别大的区隔度。大家都刷到 70% 多以后,再往上刷一点就很难拉开差距。
后面就可以盯着 ProgramBench 了。
总结:0% 不是终点,而是新战争的起点
0% 不是终点,而是新战争的起点。对于程序员来说,这当然是一个短期安慰:又活过了一天。但它也是一个更危险的信号。
第一,AI 正在向着直接从零开始完成完整项目的方向发展,而且 Benchmark 出来以后,大家会快速向这个方向迭代。
第二,AI 写的程序以后人可能读不懂,人也没有办法再到 AI 程序里修修补补。到那个时候,大家就不要再去卷“我比 AI 更懂编码规范”这件事了。
我记得在猎豹的时候,傅盛有一次抱怨过一个事情。他女儿写小学作业时倒插笔,也就是写中文笔画顺序是错的,被他老婆狠狠批评了一顿。他回来跟我们抱怨:
到现在了,大家以后都使电脑了,你管他写什么笔画呢?只要能认出来不就完了吗?你让她费这么半天劲去笔画正确,这有什么意义呢?
我们现在如果继续坚持软件工程规范,可能就像当时要求孩子写字不能倒插笔一样。
未来可能是:我们的软件可以执行,功能跟原来的软件一致,甚至比原来的软件更好、更快。因为 AI 的写法没有那么多抽象、没有那么多架构,用巨大的单体函数写出来,可能会跑得更快。每一次代码抽象,对计算机来说本质上都是一次地址跳转;少跳转几次,速度就可能更快。
所以未来方向已经确定了:AI 不再只是代码助手,而是完整软件工程师。程序员要做的事情不再只是写代码,甚至连看代码都未必需要你看,而是如何定义需求、如何验收结果、如何进行安全把控。
大家一定要把这个事情搞清楚,这就是未来的方向。
好,这个故事今天就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群。也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
背景图片
