

大家好,欢迎收看老范讲故事的 YouTube 频道。
我有一套 AI 课程,之前在会员频道里断断续续更新了一些,但已经停了很久。之所以停,是因为这一段时间 AI,特别是 AI Agent 发展得实在太快了。如果继续按照原来的课程往前走,就不太合适。现在我有了一些新的思考,准备把它录出来。不过这一期就不放在会员频道里了,就放在这里。
AI Agent 时代来了
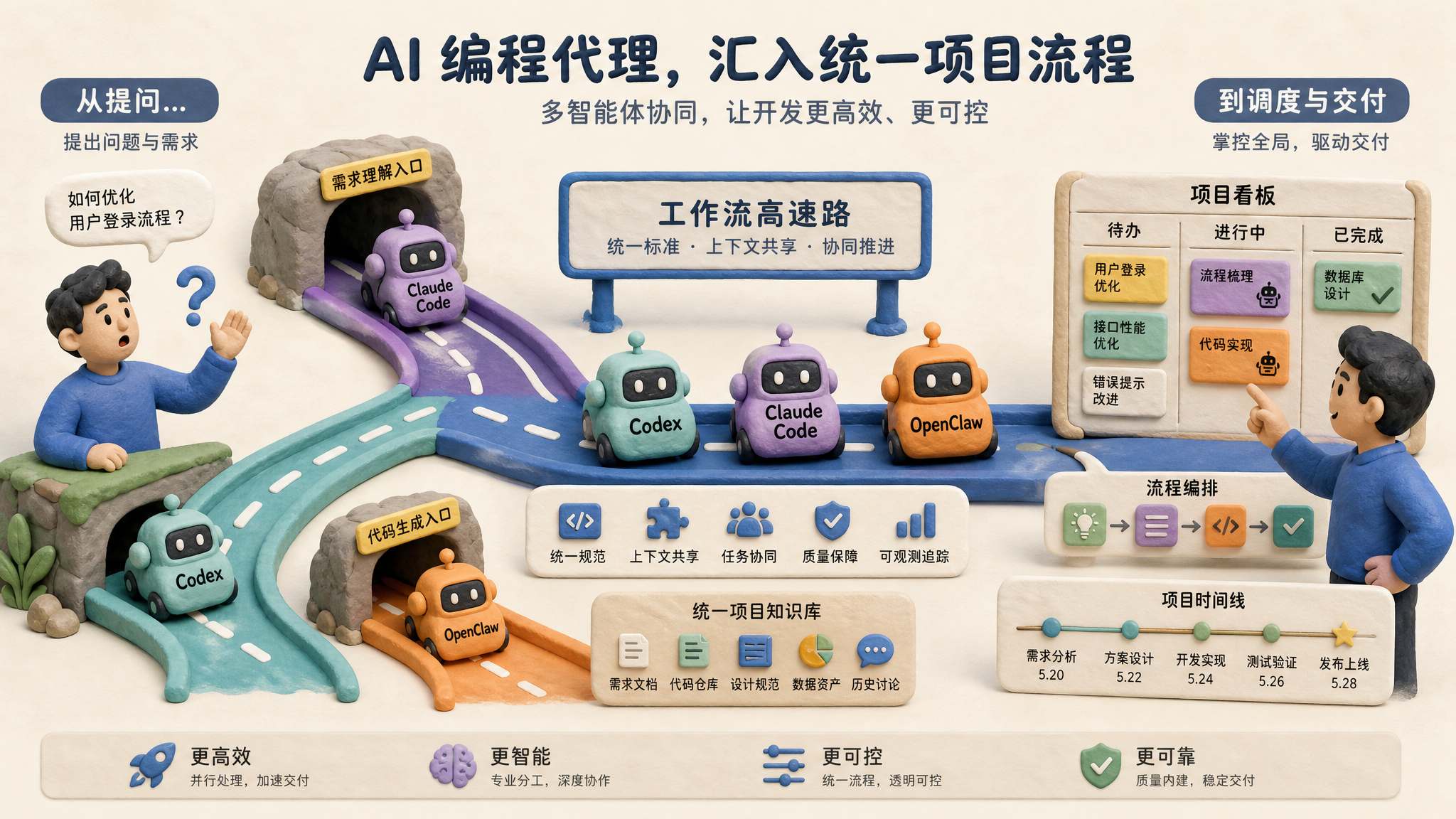
现在 AI Agent、Harness Agent、Codex、Claude Code、OpenClaw,也就是小龙虾,都来了。我们进入了 AI Agent 时代。原来说 2025 年就是 AI Agent 时代,但那时候我们其实没有那么深刻的体验。到了 2026 年,特别是 OpenClaw 热了以后,我们每一个人都深刻体会到,确实进入了 AI Agent 的时代。当然有些人说,我实在没法布置龙虾,我就用 Codex 行不行?也行。
进入 AI Agent 时代的第一个坑是什么?停止提问。
原来我们跟 AI 都是聊天,你问一句,它答一句,甚至来回对话,你不停地问,它不停地答。到 AI Agent 时代,这个事就别干了。如果你继续去提问,就属于在浪费时间。现在我们要迈入工程化的时代。
什么是工程化
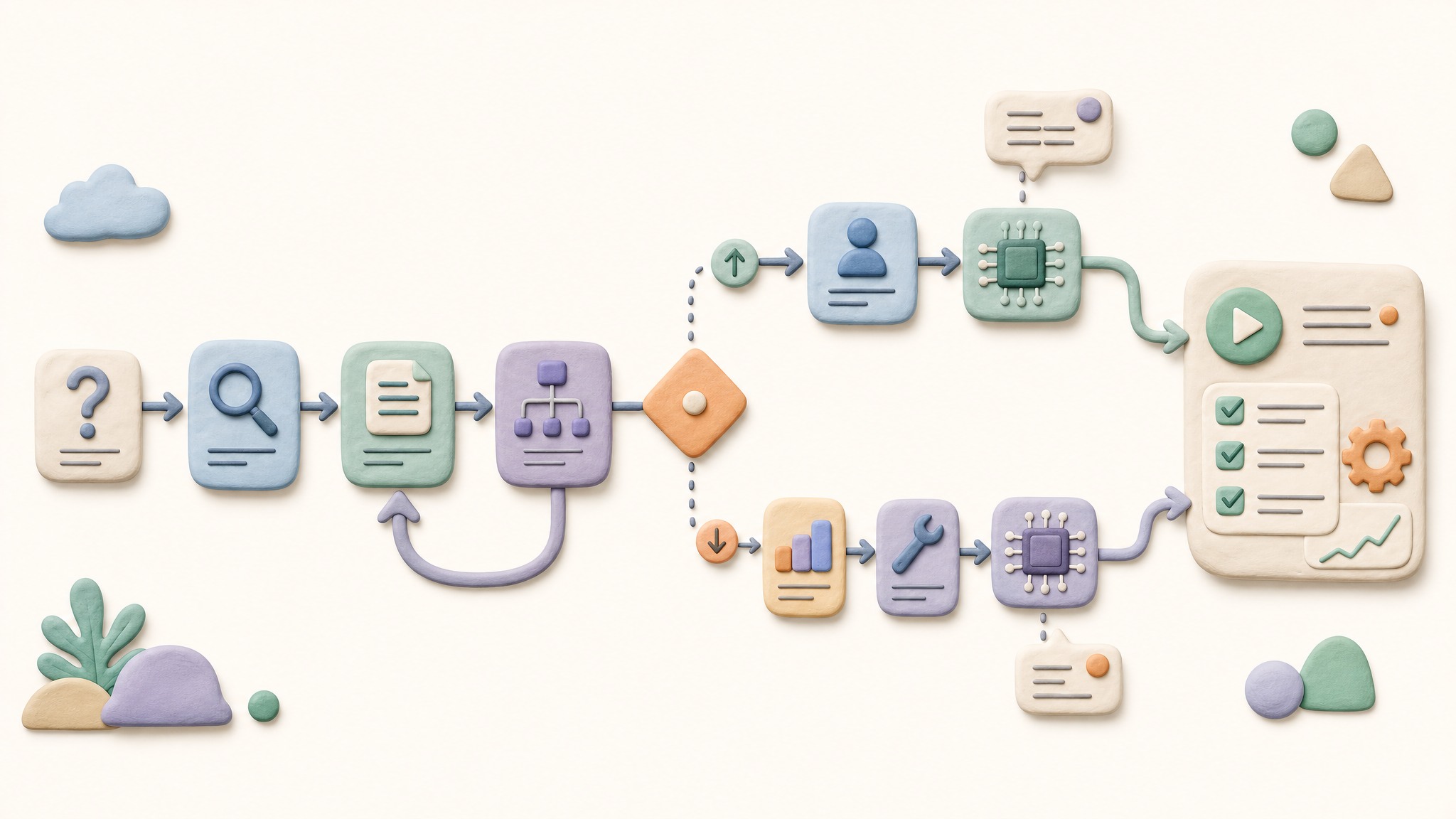
工程是一个过程
什么是工程?它是一个过程:先干什么,后干什么;如果这样,怎么样;这个事情干几遍,然后再干下一个事情。这就叫过程。即使你只是问了一个问题,它后台处理的也是一个过程。
比如你问它:
今天天气怎么样?
它不能直接拍脑袋回答你。它要先去查,查完以后再回答。而且查的时候还要确定日期,确定你的位置,把这些东西都确定以后,才会说某年某月某日在某个地区天气怎么样。这个任务一定是分步骤完成的,而且要有记忆,不能说聊完以后就忘了。
工程需要记忆
记忆不光是说它记住了某些事情,还要记住你很多习惯,记住很多规范。
比如原来你问个天气,它就给你回答了。但下次你跟它说:
记着,我每次问完天气以后,你一定要多跟我说一句,这个天气适不适合洗车。也就是我问完天气以后,你要把未来几天的天气查一下。如果未来几天都晴天,你就告诉我适合洗车。
你把这个事告诉它以后,它就记住了。下次你再问天气,它就会回答你:
今天晴天,但是未来两天会下雨,不适合洗车。
它会给你做一个这样的回答。
工程必须有边界
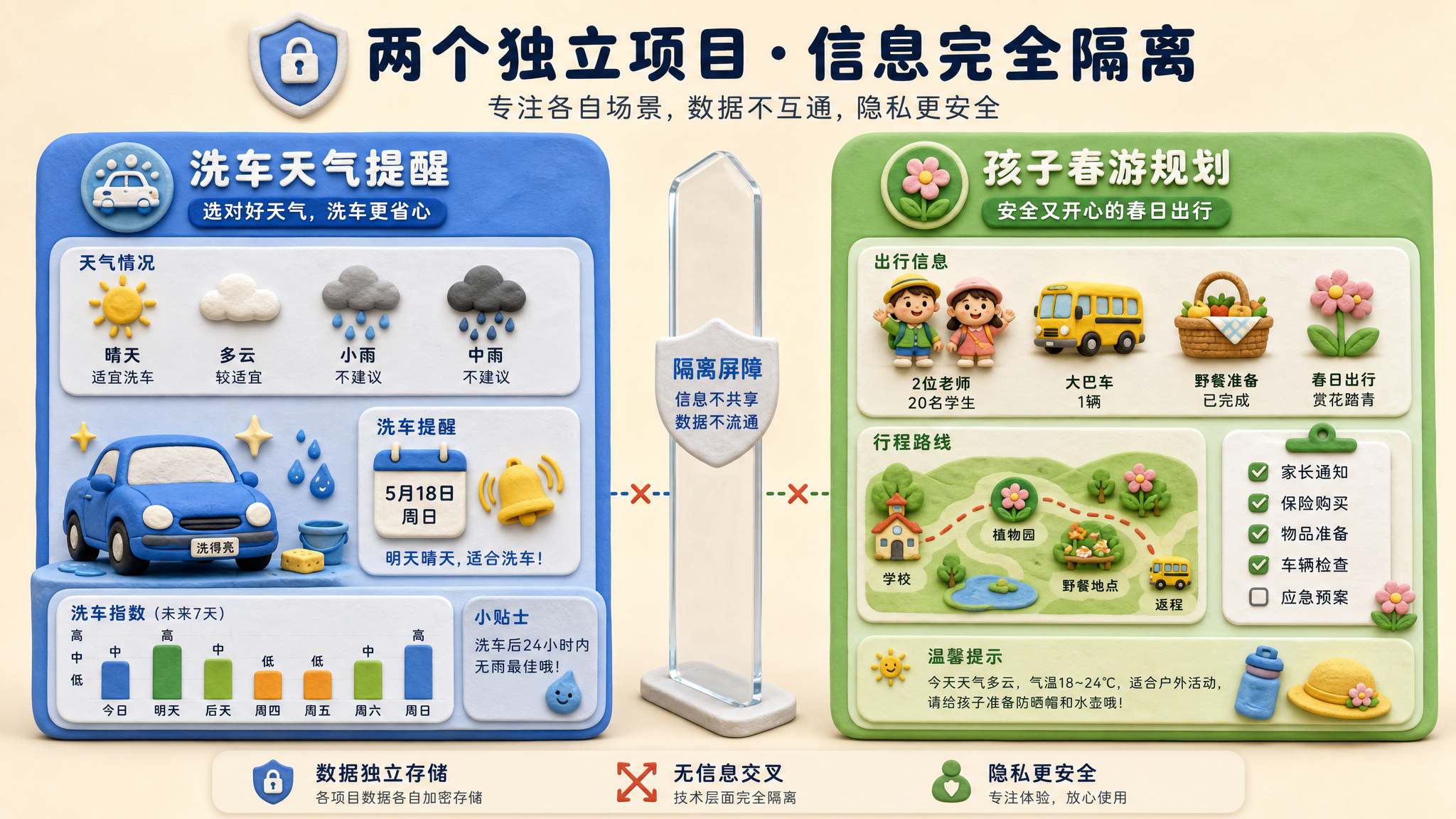
工程还有一个很重要的属性,叫有边界。很多人喜欢跟 AI 聊天,从头聊到尾,不停地给它上传文件,不停地下载文件,这个叫没有边界。一个工程跟一个工程之间是分割的,不要进行相互之间的数据污染。
也就是说,你就根据这一个工程和项目里我给你的这些信息回答我;换一个工程和项目的时候,你就不要再给我回答这些事情了。
还是问天气的例子。你默认让它记住了,每次告诉你要不要洗车。下次你说:
我们现在开一个新的工程,在这个工程里,我们要给小孩规划春游的事情。
这时候你再去问天气,就换了一个场景。这个边界里没有原来那些记忆,你换了一批记忆。你说:
现在天气怎么样?给我找一个适合出去春游的天气。
它就不再回答适不适合洗车这个问题了。所以一定要注意,工程是有边界的。
工程要计算投入产出比
所有的工程都要计算投入产出比。我花了多长时间,得到的这个结果是不是好的?在问答的时候,可以有一个 0、1 的结果,就是这个事情对了还是错了。但是做工程没有 0、1,只有好和更好、坏和更坏。每一件事情都是有程度的。
为了得到一个更好的结果,我愿意付出多大的代价?付出这个代价划算不划算?所有工程上的事情都要去计算,要去评估结果的质量。工程的结果是有打分的,要想办法让它更好一点点。
工程要不断迭代和优化流程
问天气这个过程,可能包括:先查询你的地址,确认日期,再找一个合适的天气问询网站。问询以后,再去查一下原来你给了它什么提前的指令,或者记忆里有什么东西,然后把这些东西合成一个结果发给你。
这个过程是需要不断优化的。比如我觉得换一个网站去问更好一点,因为国内经常苹果天气不太准,用小米天气、华为天气会准一点,因为它们是从不同的网站得到的天气信息。这就是一个工程应该有的东西。
所以我们现在进入工程时代了。第一件事就是不能再提问了。我们要想清楚,我们是在跟什么东西打交道,是跟工程打交道,工程包括哪些属性。
AI Agent 时代会遇到的新坑

进入工程以后,我们会遇到一些新的坑:
- 宏大叙事:我无所不能。
- 边界不清晰。
- 不进行边界拓展。
- 将就凑合。
- 想重新改变和规划底层的开发过程。
- 失去自己的参与。
坑一:宏大叙事,以为自己无所不能
很多人到了 AI 时代以后说,没有什么是干不了的。我刚才还在 X 上看了一个神帖,说他的领导告诉他说:
咱们以后不要花钱在外边用 DeepSeek 了,咱们自己开发一套。
发帖的人出来抱怨,他还是比较理性的,说领导买个好点的显卡,我们上 Ollama,上这样的系统,部署个 DeepSeek 也能使。他领导说:
不用好显卡,我们就用破电脑,咱们自己开发一套就行了。你如果不会写,就让 AI 给你写。
这就属于以为自己无所不能。
还有些人上来就说,咱做个微信吧,做个 YouTube,做一个 3A 游戏,甚至说我做个操作系统,我自己再开发个 DeepSeek。其实前面这几项都还是有可能做出来,但最后一项肯定做不出来,就是你让 AI 去给你做个 DeepSeek。
为什么?这就相当于有很多人教大家去买彩票,告诉你怎么买彩票能中奖。他自己要真能中奖,早就自己做去了。所以如果 DeepSeek 自己真的用 AI 可以把自己搞出来,它就不会停在现在这个位置,它会继续往前走。
千万要注意,不要一上来就想一口吃个胖子。一定要观察自己的需求:我原来是干什么的?我原来干的这个事情有什么地方可以进行优化和改进?到底什么是我真正的需求?什么是我现在的问题?这些问题在有了 AI 以后,到底会有什么样的变化?这是我们真正需要思考的。
所以宏大叙事和“我无所不能”,并不是说你真的被 AI 教坏了,而是我们没有对自己身边真正的需求进行认真的观察和思考。拿到 AI、拿到 AI Agent 以后,第一个要躲的坑,就是避免宏大叙事,避免“我无所不能”的思路,而是在身边,在你原来做的这些事情里,认真观察和思考,找到细微的、具体的需求,把它解决掉。
坑二:边界不清

每一个项目上来以后,你要想得到预期的结果,注意我讲的永远不是正确的结果,而是预期的结果。
因为我们现在在工程里面,你到底给了它什么样的资源,给了它什么样的数据,给了它什么样的上下文,准备花多少 Token,花多少钱和多少时间,预期要得到一个什么样的结果,这些东西是捆绑在一起的。不是说我一定要最好的结果,没有最好的结果,只有预期的结果。
如果我们想得到预期的结果,就要搞清楚一件事情:我到底要投入哪些东西?哪些记忆应该是它的,哪些上下文或者文件应该是它的。你不要去参考那些跟你没关系的事情。
一旦参考了这些没关系的事情,会出现两个问题:
- 浪费非常多的 Token。因为你把大量无用的信息塞进去,它不知道该怎么取舍,只能通通都读一遍,一起去思考。
- 最后得出来的结果大概率不是你想要的。
还是问天气的例子。正常情况下问天气,它会告诉你是不是该洗车。但你今天要给小孩规划春游,就不需要把洗车这个提示词,或者叫上下文,注入到现在这个任务里去。所以你要用边界把它隔开。
正常的工作方式是:每一个任务开一个新的项目。不管你是在 Codex、Claude Code 还是 OpenClaw 里,开一个新的项目以后,你的上下文是干净的,前后都没有。然后再说:我现在给了你哪些文件,你现在在哪些文件的范围内、在哪个目录的范围内,我们来做什么事情。
有的时候你实在搞不清边界在什么地方,还可以先问它:
你有哪些技能?你这个记忆里,在哪件事情上是怎么约定的?
你可以先确认一下,再开始往里喂文件,然后开始干活。所以工程非常重要的一点,是边界清晰。
坑三:不进行边界拓展
讲到边界,下一个问题就是不进行边界拓展。
原来我们处理一个任务的时候,因为能力有限,阅读速度、思考精力都有限,所以会在一个比较小的边界范围内做事情。现在有了 AI,我们可以处理大量信息了。我们可以说:
你去把什么信息都找出来,我要读一读。读完以后,你给我总结归纳。
比如给小孩规划一个旅行,以前是根据自己的经验,再查个小红书、查个携程就完事了。现在有 AI 了,你可以让它把天文、地理、历史、人文通通汇集起来:在哪个地方应该拍照打卡,在哪个地方有什么好吃的,这个好吃的有什么历史风俗,是怎么传下来的,吃什么东西需要注意什么,家里孩子对什么过敏。
你可以把所有这些东西都放进去,或者说你能想到的东西都尽可能往里放一放。这样你得到的结果就会有巨大的提升。
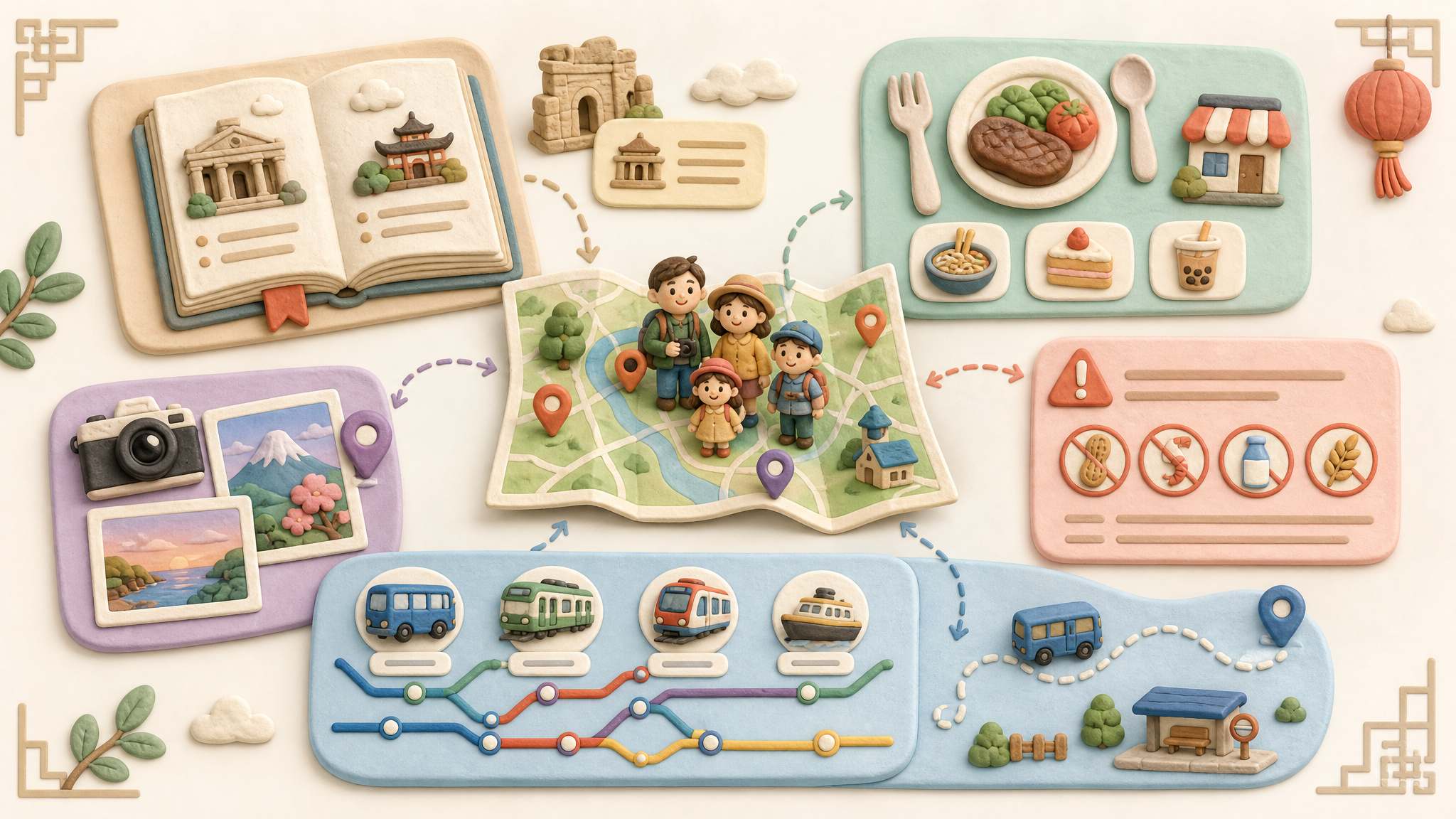
很多人说,我现在用 AI 了,但我不拓展边界,我原来输入什么信息,做哪些工作,现在还这么干,那就没有意义。降本增效只能带来裁员。怎么能够在有 AI 的情况下把这事干好?就是要拓展你的能力和信息边界。
大家现在看老樊的很多节目会发现有一个变化,不管我现在是不是照着 AI 念稿,但是我现在讲的故事里,数据、人物、时间要比以前多很多。
因为原来我是靠自己的经验、靠自己的记忆给大家讲故事,就算可以再进行一些阅读,阅读速度也是有限的。现在我可以让 AI 去整理大量信息:有哪些事件、有哪些交易、谁花了多少钱、买了谁多少东西、过去是什么样、增长了多少、下降了多少、百分比是什么样、是什么趋势、别人做了什么评价、谁做了哪个报道。
这些东西我不用挨篇把文件都看一遍,只需要把这些数字念上,细节就丰富了很多。而且我在总结归纳、形成结论的过程中,确实参考了这么多内容。虽然我不是一个字一个字念的,而是让 AI 帮我总结归纳的。我现在做节目的过程中,所阅读的内容,或者所处理的信息边界,已经比早期扩大了非常多。
坑四:将就和凑合
我们每个人的工作总时长其实是固定的。一天比如 8 小时也好,10 个小时也好,就算你在办公室坐了 12 个小时,真正高强度、高专注的工作也就是一天三四个小时或者五个小时。很多可以自动化的东西没有被自动化,但事情也做完了,很多人会选择到此为止。
我们肯定是在很多碎片化的地方发现可以靠 AI 优化的点:这个地方有一个小碎片,我把它处理掉了;那又有一个,我又把那个小碎片处理掉了。但这两边一开始是接不上的。
现在有 AI Agent 了,你可以把它接上,可以把这两个环节自动化起来,甚至可以把多个环节自动化起来,这个事都是可以搞定的。
不要将就,不要凑合,不要说我现在已经可以得到结果了,就得过且过。AI 能力的拓展、自动化不同流程的对接,本身是需要成本的,需要搭建、测试、debug,这些都需要时间。
所以千万不要停在原来的地方不动。一旦这样,整个效率提升的过程就会停下来,你就不能处理更多的任务了。有了 AI Agent 以后,我们要在有限的工作时长里不断压缩任务,让原来没有那么自动化的事情慢慢自动化起来。
坑五:过程不迭代、不优化
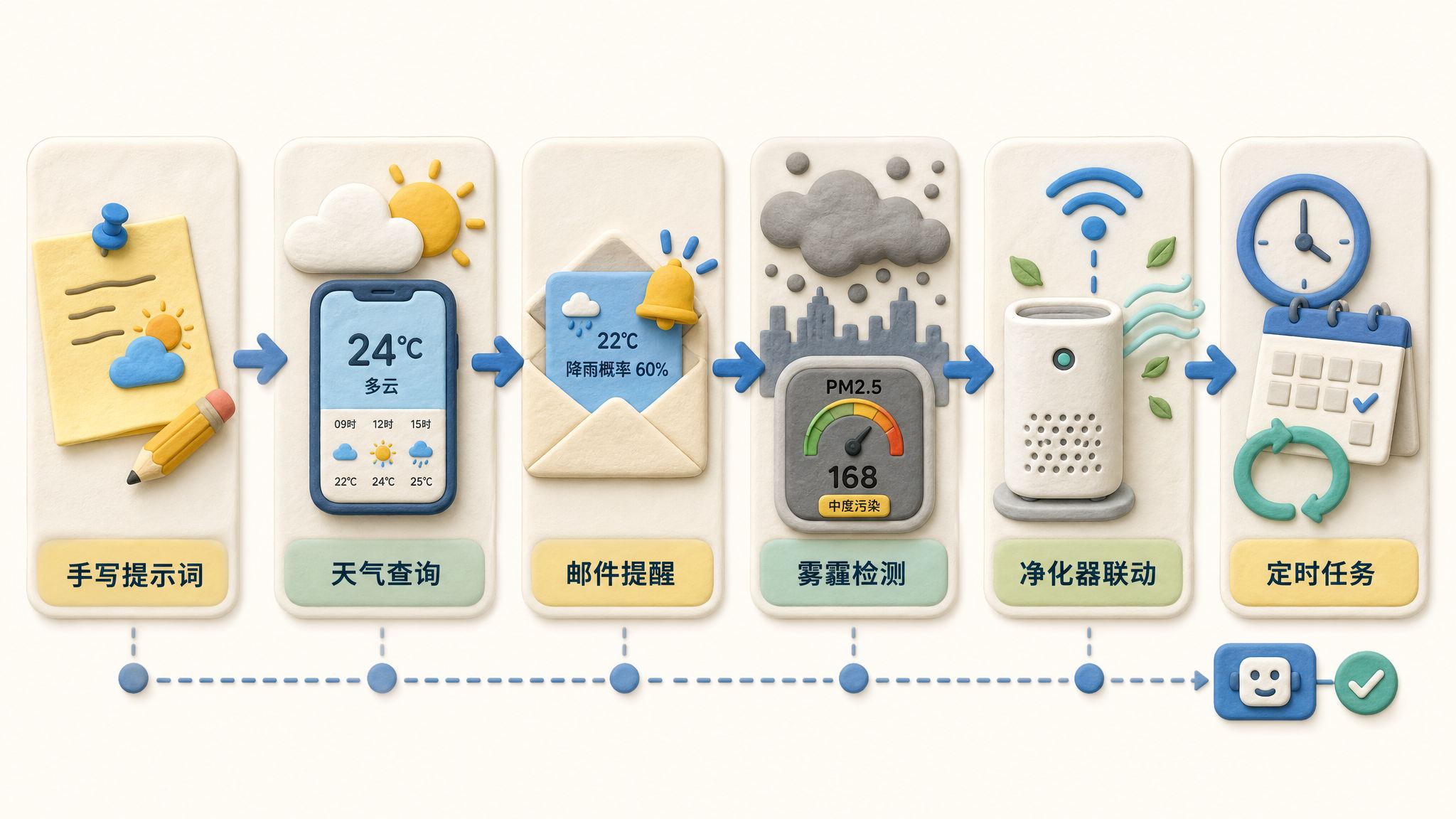
工程时代了,不能再去提问了。我们要做的是沉淀和迭代流程。
比如你现在去问天气,每一次先确认我的位置,确认我的时间。有些人会出差,比如今天在北京,然后出差去上海了。我问天气的时候,希望你顺手把北京的天气也跟我说一声,我可以跟北京的家人说一下,要晒衣服了,要收衣服了。
你每一次问天气的时候,都给它描述一遍吗?如果你不描述,它记不住。那怎么办?你就要去沉淀这个技能。
请记住,下一次我要用一个单独的技能,你给我起一个名字,叫日常天气查询。如果我在北京,你就去做 1、2、3;如果我不在北京,你要在我当前的城市给我进行查询,然后你还要告诉我北京的情况,再做 1、2、3。
甚至有的时候可以说,我查完天气以后,请自动给谁谁谁发一封邮件。这个事情是可以固化下来的,而这个过程叫技能固化。
做完以后,后面又在不断地跟它聊这个天气。比如还要查一些雾霾之类的事情,如果雾霾大了,即使我不在家,也得提醒家里人关窗户。而且我希望控制家里的空气净化器直接开机,但是开机之前最好把窗户关上,要不然就浪费滤芯了。这个过程就叫迭代优化。
你要告诉你的 Codex 也好,Claude Code 或者 OpenClaw 也好:
请迭代优化我原来的这个技能,把哪些功能加进去。
你跟它沟通以后,发现结果有不满意的地方,可以说:“我再教你一遍。”这跟带个实习生似的。再教一遍以后,等下次它再做的时候,你希望它记住。
为什么我很少使用 Harness Agent?Harness 就是马具。Harness Agent 会自动给你迭代进去。我比较喜欢用 OpenClaw,比较喜欢用 Codex,它不会自动给你做迭代,必须要手动告诉它。这块边界比较清晰:这个事我告诉你记住了,你就记住了;如果我没告诉你,下次你不要画蛇添足。这是我目前比较习惯的工作方式。
还是天气这个事。做天气查询以后,要做技能的沉淀。假设我问完天气以后,发现今天是阴天,而我天天出去拍摄,要拍室外视频,那你要给我发一个邮件,告诉我今天出去拍视频的时候,请把摄像机设置成什么样的白平衡、什么样的曝光强度,要做一些个性化设置。
这个在 AI Agent 里都可以搞定。但是这一次你做了,下一次有可能你就忘了,那你拍出来的视频颜色就是偏的,就不好看。以后每一次查了天气以后,它就会自动告诉你:今天是这样的天气,你这个摄像机是需要进行调整的。
你跑了一段时间以后发现,天气预报这个事每天都得问,以后就别让我问了,你每天早晨七点钟还是八点钟自动去跑,跑完以后给我一个结果。这个也可以,这也是一个技能固化的过程,就是把一个技能固化成一个叫定时任务的东西。
像我现在每天早上起来,会要求我的龙虾定时去搜集各个播客,比如纳维尔、丹蔻这些人的播客上都写了什么东西,再把各个媒体都搜索一遍,给我一个总结、一个简报,告诉我今天大家都在讨论什么样的事情。这个我都已经固化成定时任务了。当然我并没有把天气这个事固定下来,因为对于我这个每天宅家的人来说,天气到底怎么样意义不是特别大。
坑六:想重新改变和规划底层开发过程
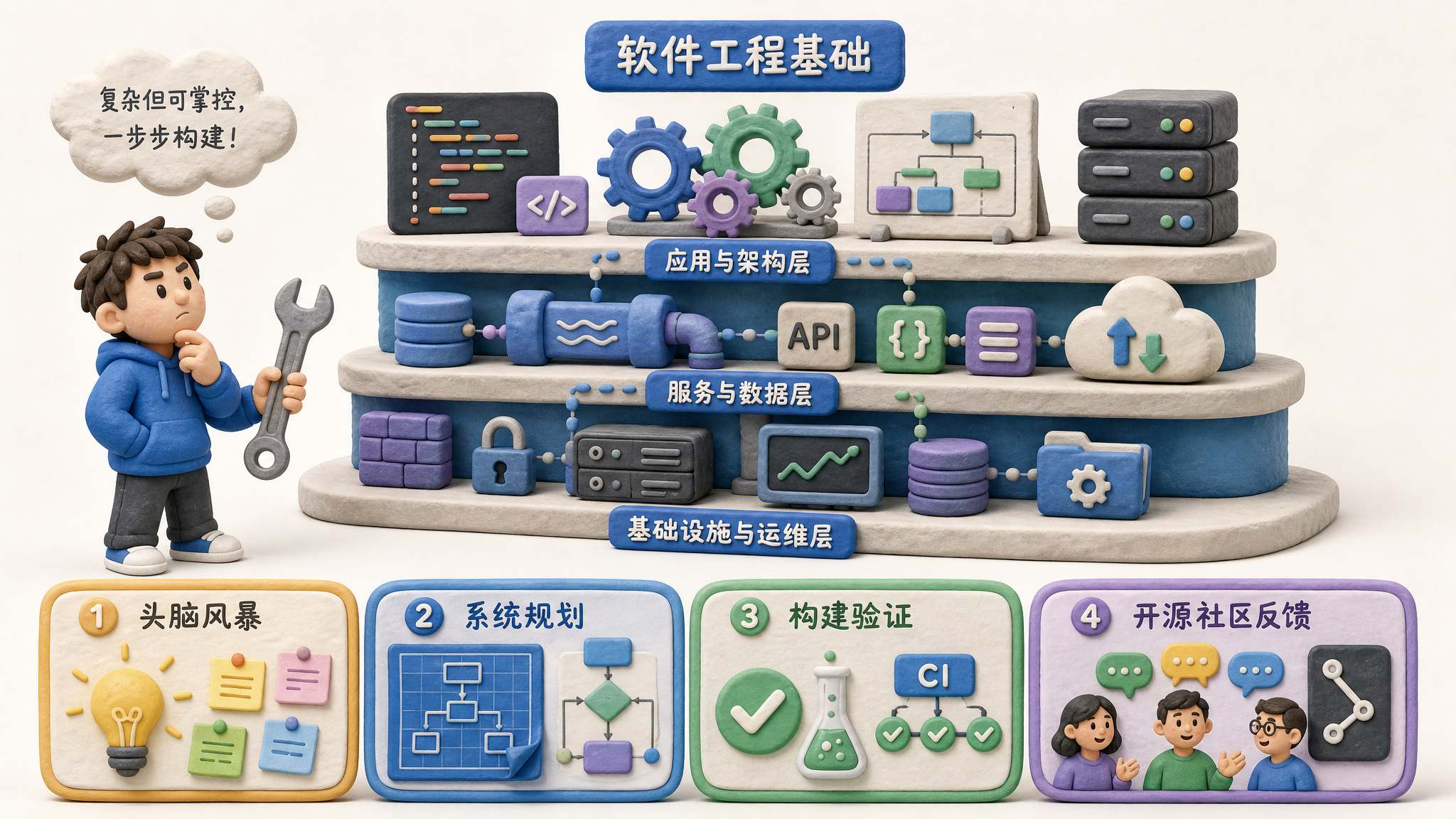
还有一个比较有意思的坑,就是我要重新改变和规划底层的开发过程。
你可能会说,我们都在不断迭代了,那我为什么不能把底层改掉呢?因为正常的底层开发过程是:先做头脑风暴,做完头脑风暴,然后明确所有描述不清晰的点,再进行系统规划,进行系统构建。构建以后,再进行结果的验证。正常的开发流程是这样的。
很多人写着写着说:“我觉得这个流程不好,我想换一个流程。”这个事不要上来就干。
为什么?因为这个东西实际上叫软件工程。软件工程是一门很严肃、投入了非常多人力物力形成的学科。当然不是说人家已经形成了你就不能改,肯定还是能改的。但是一个新人,特别是一个非程序员出身的人,对于完整的开发过程、大规模开发的过程、不同角色团队配合的过程是没有认知的。
特别是在刚开始接触 AI Agent 的时候,缺乏理解和认知。你可能对于自己想干什么很明白,但是对于怎么跟人配合,就没那么明白。
你说我就自己干,我又不跟人配合。要注意,我们在 AI Agent 里,是跟一堆 AI Agent 的不同角色配合的。所以你要有这样的多角色团队配合经验,才能够去改底层开发逻辑。
我为什么跟大家录这个视频?有一个原因是,上周六我儿子从学校回来说:
我现在用 Codex,我要去改一下这个底层的东西,我要把这个软件工程的东西改一改。
后来我说,你现在先别干这个,还是先用现成的东西。把现成的东西用会了以后,你发现哪里不好使,可以在那个基础上提问题。向谁提?因为是开源社区,你可以向开源社区、软件工程这些开源项目的 owner,向它们的所有者提问题,说我为什么使得不顺畅,是不是应该改一改。
人家会建议你换一个方式去使用。实在不行,你就改它那个项目也可以。改完以后,如果你还希望别人也这么用,还可以再 pull request,把它提交回去,都是可以的。
但是你不能上来啥都没看,不知道人家怎么玩的,一拍脑袋就去改这个东西。所以还是要有一些敬畏心,先学习这个东西底层到底是什么样的,向 AI 学习,使用现成的开源项目和代码。如果你使用得不舒服,可能不是原来的过程不合理,而是你还没学会。
即使你不写软件,而是做文稿,做其他的事务性工作,最好也是去学习一下现在的软件工程技术。通常非程序员早期不要去碰这种大规模项目。如果碰了,先思考一下:我真的要干这事吗?通常你在早期遇到这种大规模项目的时候,是你想歪了,不是你真的需要去做。
如果一定要做,可以从一个项目开始,这个项目叫 Superpowers,就是超级能力。这个项目是一个相对比较简化的,或者比较中等的软件工程辅助。现在的 Codex 和 Claude Code,包括 OpenClaw,在这块还要稍微差一点点。
你需要先去做头脑风暴,然后进行规划的编写、规划的并行执行,再进行结果的验证。它会把整个流程给你梳理过来。但是要注意,这种工具是给中大型项目使用的。换句话说,如果你在很小的项目上使用这种工具,会比较浪费时间和 Token,所以使用的时候一定要谨慎。
坑七:失去自己的参与
很多人在使用 AI、跟 AI 聊天的过程中会遇到一个问题。特别是很多课程会教你:这个技能特别好,赶快装一下吧;使用 OpenClaw 龙虾必装的 5 个技能;使用 Codex 必装的 10 个技能;还有人写说,使用 Codex 五个月,装了 200 多个技能,最后只剩下这 5 个。
这种标题很好,但是没有任何意义。不用想着我要装这个技能、用那个技能,没有意义。自己慢慢去沉淀。
还有很多人会打广告,说不用出镜就可以录视频,完全自动化,一键生成,只要点击就有小说,马上就可以有收益。别信这个。
我们使用 AI,但是一定要注意,自己才是核心。虽然活都是 AI 干的,比如我们在公司上班,下面有人吭哧吭哧把活都干了,那这事是他的功劳吗?不是,一定是上面的领导管理有方,指明了方向,这才是最大的功劳。所以 AI 也是这样,AI 吭哧吭哧把活干了,还是我们这些指明方向的人要在里面真正发挥作用。
人要参与什么

我们要发挥的作用,首先是理解任务。我们要搞清楚,我到底要干什么,要发现问题。
然后有一个非常重要的参与点,是要体会感悟。AI 输出了稿子,不能直接把它交上去,也不能直接往下一个环节传。我们要自己看,看完以后要想一想:这东西真的是我想要的吗?这是我说的话吗?表达了我的意思没有?我会不会产生一些别的、不同的结论出来?这个很重要。
像我现在做口播,都是先让 AI 搜集信息。把原始信息读完以后,我会形成一些结论,然后让 AI 帮我梳理。梳理以后我会再读,读完以后我不会让它马上干活,我会休息一下,起来逛荡逛荡,或者去做一些其他事情。
这个时候,这些信息会在我脑子里沉淀,我会有自己的感悟,会有自己的感受。然后我会把这些感受重新描述给 AI,说我觉得哪个地方不太好,或者我还有一些这样的东西,你给没给我表达出来,我还想表达一些其他的事情。你要把这些东西跟它描述几次,迭代几次以后,它会给你一个结果。
这就是我们自己参与的过程。我们会不断把自己的体会和感悟加入到这些结果里去。
而且在这个过程中,我经常还会调整方向。比如一开始我看到了一个标题,看到了一些原始资料和数据以后,会形成一个结论,想跟大家讲这些事情。我让 AI 搜集了很多信息,做了一些深度研究以后,有可能有一些新的点想讲,或者有一个不同的结论想告诉大家,那我会告诉它:
我们现在换一个方向,我现在想强调一些不同的重点。
再往后是要检查和评估结果。在这个过程中,我要看每一个版本之间到底提升了什么,降低了什么,怎么变得更好了。没有绝对最好,只有更好。怎么变得更好了,到底好在什么地方,这是我们要不断去做的东西。只要我们参与到这里面,最终的结果就不是 AI 生成的,而是我们指挥 AI 生成的。
不要什么都从头干

还有些人是什么都想自己干。不要什么都自己干,有大量现成的东西。
也不要去问 AI:
我有一个思路,我是独创的吗?我是不是独创的?我是不是创新的?
这个问题一把就把 AI 带偏了。因为你一问这个事,AI 是个讨好型人格,它一定会告诉你,你是独创的。
再接着讲我儿子的案例。我儿子前面回来想重新做这个软件底层开发过程,他也去问 AI:
我这个想法是不是独创的?
AI 说:“你就是独创的。”然后他吭哧吭哧地在那坐了半天。
所以不要去问 AI“我是不是独创的”,而是要问:
我现在有这样的一个需求,有没有现成的?现成的方案跟我的需求到底有哪些差异?
因为你每次问它以后,它会给你三四个,不会只给你一个结果。它说这几个方案可能都比较相近,哪个更近一些,哪个稍微差一点点。给你这个结果以后,你要在里面去挑选,挑选以后再去进行测试。
它通常给的结果都是开源软件,你到 GitHub 上把这些开源软件拉下来就可以了。而且现在大量的结果都是开源技能。你已经在 Codex 里,已经在 OpenClaw 里了,你可以在技能库里直接要求它装这个技能。
财报分析的例子
比如我们今天想做一个上市公司的财报分析,这个事应该怎么办?是不是应该向它描述:
我现在想去分析上市公司财报,请你先读财报,然后再根据财报里面哪些数据去进行评估,然后找一个标准财报模板,看看哪块说了、哪块没说。因为有的时候没说的部分才是重要的部分,缺的是什么东西。这个财报的增长和下降,跟它过往的数据怎么比较,跟同行业其他竞争对手怎么比较,最后给我一个梳理的结果。
不应该这么干。
应该先让 AI 帮你找:
有哪些现成的财报分析技能?
一定有现成的,这不用想。它会告诉你,现在有这么几个。然后你问它:什么叫好?什么叫不好?你要有自己的评估标准。比如哪个用户量大,哪个星多。
什么叫星多?就是在 GitHub 上,如果我们关注一个开源项目,会在上面打一个星星。关注的人多,这个项目质量就比较高,而且它迭代比较快。
所以你要看哪个用户多,哪个星多,还要问哪一个项目或者哪一个技能的社区比较活跃。社区不活跃的话,万一你把这东西拉回来使用的过程中发现有问题,问都没地方问,或者你问了以后没人理你,这事也很讨厌。
你把这几个要求提上去以后,它就会给你推荐三四个。你要把这三四个再筛选一下,然后再试试。实在不想试了,就说:
你现在给我推荐一个,我要最合适的。
然后你把这个最合适的财报分析技能拉回到本地,拉回到你自己的 AI Agent 平台上去,让它开始干活。
然后在这个基础上干什么?我觉得哪儿不满意,帮我改一改,这才是该干的活。所以千万不要从头开始干。要在这个基础上,先找到最好的、最活跃的、最新的、用户量最多的、评价最高的。找回来以后,你用的过程中不爽了,可以要求 AI Agent 平台给你做迭代。
比如这一次,我发现你只对比了美国公司的,没有对比同行业中国公司的,这块是缺失的,请在这一块进行补充,然后把整个过程更新迭代到技能里去。下一次你再做美国上市公司的财报分析时,它会把同行业里的中国公司,或者它上下游相关的公司也都找出来,分析好以后写在报告里。这就是这样的一个过程。
所以千万不要从头干,每件事情都不要从头干。你说这事我实在是问了 AI,它确实说你就是最新的,谁都没干过,那你再从头干。但是注意,问 AI 的时候千万不要问它:“我创新了吗?”因为 AI 是讨好型人格,它会骗你的。
总结:AI 时代,所有人都要用工程化思路做事
最后总结一下。AI 时代,所有人都是程序员了。如果你原来不是程序员,建议你好好看看今天的节目,用工程化的思路去面对我们当前的任务。
在 AI Agent 时代,我们要去做只能由人做的事情。什么是只能由人做的事情?
- 理解任务,发现问题。
- 不断体会和感悟这些数据和结果。
- 把你的体会和感悟重新迭代到过程中去。
- 不断调整方向,不要上来就咬定青山不放松,方向是可以调整的。
- 检查和评估结果。
- 不断迭代和优化过程。
- 不断拓展你的信息边界。
这就是人可以参与的部分。
所以在 AI Agent 时代,如果您在听我的节目,原来不是程序员的话,希望这一期节目对你有所帮助。
好,今天就讲到这里。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
背景图片
