

GPT-5.5和DeepSeek V4在同一天前后发布,AI竞争进入了一个新格局。2026年4月23日和24日这两天,全球AI产业迎来了一场小小的地震,而且这次地震很有意思。
同日发布背后:AI竞争进入新阶段

GPT-5.5发布后9个小时,DeepSeek在杭州发布了V4。要注意的是,这次发布和前几天GPT Image 2的发布形成了鲜明对比。
OpenAI过去每次发布重要版本,通常都会开发布会,至少也会有线上直播。但这一次什么都没有,直接就上线了。前几天GPT Image 2发布时,Sam Altman还陪着一屋子亚洲面孔的小哥讲了一晚上,除了他之外,剩下的人里大概有两到三个中国人,可能还有一个日本人、一个韩国人,几乎只有他一个白人。然而这次GPT-5.5什么仪式都没有,直接推送给Plus、Pro、Business、Enterprise用户使用。
DeepSeek V4这边则是发布之后直接开源,本身就是一个开源产品。这意味着,全球AI竞争从此进入了一个新的阶段,不再只是比谁家的模型更强,而是开源和闭源、高价和低价、算力自主和算力依赖这几条主线开始正面交锋。
GPT-5.5发布方式反常,真正重点却不是模型本身
先说GPT-5.5。这次发布方式在OpenAI历史上都很少见。我今天早上起来,是Codex提示我升级,GPT的App也要求升级,网页打开以后就直接变成5.5了。
其实这次真正卖的并不是GPT-5.5本身,真正的重点是前两天发布的Codex,待会再讲为什么。
很多人一上来就看指标,觉得GPT-5.5很厉害,很多指标一下成了世界最强,在大多数指标上超过了Opus 4.7,好像OpenAI又回到了世界老大的位置。但现在所谓大模型到底有多强,这件事已经没那么重要了。真正重要的,是模型在三个地方的表现。
1. 编程能力
像GPT-5.5或者Opus 4.7这种好的模型,可以用很少的Token快速找到答案,不会四处乱转。如果是比较差的模型,可能会绕来绕去,搞不清到底出了什么问题。
即便是相对差一些的模型,放进Claude Code、OpenClaw这类Harness Agent框架里,事情也能做完,只是有的做得更痛快一些,有的慢一些,差距没有想象中那么大。
2. 文档处理、知识工作与搜索
第二个是处理文档、知识工作和搜索,这也是我自己用得最多的场景。就我现在的使用体验来看,即使是笨一点的模型,你放进OpenClaw或者Azure里,差异其实不大。
真正的区别在于配置兼容性。OpenClaw现在和OpenAI的兼容性最好。你说不给你配OpenAI,改配MiniMax行不行?也不是不行,只是每次升级时都得提心吊胆,这个比较痛苦。
3. 解决特别难的问题
第三个差异是在解决特别难的问题上,比如一些数学难题。这次GPT-5.5出来后,有数学家说,它把人类数学又往前推进了一步,这当然很强。
但这一块普通人是无感的,因为大部分人根本看不懂它到底做了什么。我自己看了半天也没看懂。你跟大多数人讲它到底干了什么,大部分人都理解不了。这块中国确实还差一点,我们压根没在这方面怎么努力。
GPT-5.5发布前的小插曲:泄露与回收

这次GPT-5.5发布还有一个很有意思的小插曲。发布前一天,GPT-5.5泄露了。在Codex的App里,可以看到GPT-5.5以及另外两个还在测试、尚未发布模型的名字。
随后OpenAI直接把模型收回,还把Codex的用量重置了。像我们平时每5小时有一个用量、每周有一个用量,因为它自己放错了,就给大家重置了一把。4月23日社区里,或者X上,确实有人在讨论这件事,但OpenAI官方并没有出来承认或否认。
为什么说Codex才是OpenAI真正的重点

为什么说Codex才是最关键的?因为OpenAI现在真正要竞争的,不是去解什么世界级数学难题,而是如何争抢用户、如何维持自己老大的位置。
Anthropic现在已经说自己是老大了,年化收入300亿美元,OpenAI是250亿,差了50亿。估值方面,OpenAI是8500亿美元,而Anthropic已经可以说自己是一万亿美元。现在真正要抢的是,谁能做出更好的Harness Agent工具,或者说agency workbench。
OpenAI已经明确把重心转向这一块。Sora、成人内容、广告节奏这些都不是最重要的,最重要的是去和Claude Code抢agentic workbench市场。OpenAI自己也说了,要做超级App。
哪个才是超级App?我今天把机器上所有OpenAI的App都升级了一遍,结论是Atlas,也就是OpenAI自己做的浏览器并没有升级,所以这条线的重要性大概率在下降。反而是Codex一上来就升级,而且最近几天简直像疯了一样,经常一天升三次,因为我自己经常用,它会不停提醒你升级。这才是它真正的超级App。
为什么不是ChatGPT网页版,而是Codex?
为什么ChatGPT网页版不是超级App,而Codex是?因为你要调用本地文件,要在本地打开各种应用,要在本地进行电脑操作,要在本地打开浏览器。这些事情如果你只在chatgpt.com网页里做,是不可能处理本地文件和本地App的。
你说那用ChatGPT App不也可以吗?这里就有一个问题:如果你使用ChatGPT App,20美元套餐、100美元套餐、200美元套餐,现在主要区别只是有些模型能不能用。而如果你用Codex App,它是按流量算钱的。
像我买了20美元的Plus账号,Codex额度就得省着用;如果买200美元的套餐,就可以敞开用。对于OpenAI来说,它当然希望更多人订200美元套餐,这符合它的商业逻辑,也符合它的商业叙事。
所以,OpenAI押注的超级App就是Codex,因为它真正的竞争对手就是Claude Code。现在很多SaaS软件崩盘,法律圈不行了、金融圈也不行了、安全软件也在崩,很多冲击都来自Claude Code。现在Codex就是要正面对杀。所以这次真正发布的,不只是GPT-5.5,而是给Codex使用的整套能力。
GPT-5.5是否全面碾压Opus 4.7?并没有那么夸张
那么GPT-5.5是不是全面碾压了Opus 4.7?是不是所有领域都领先了?这事没那么夸张。GPT-5.5在大部分主要指标上确实压过了Claude Opus 4.7,但OpenAI自己给的表格里也承认,Opus 4.7有几个指标依然领先。
Opus 4.7仍领先的几个指标
- 真实GitHub软件工程任务:要求模型修复真实开源项目的代码、理解整个代码仓库、通过测试套件。这是最接近“能不能在真实项目里干活”的指标。在这一项上,Opus 4.7依然领先。
- 金融分析代理任务:测试模型在金融场景下检索数据、构建模型、财务推理、调用工具的综合能力。这一项里,Opus 4.7也依然领先。所以如果你是炒股的,或者做金融相关工作,还是老老实实用Opus 4.7,不要轻易转。
- MCP Atlas多工具协调任务:用来衡量agent使用MCP跨系统完成任务的能力。这一块Opus 4.7还是领先。
- 跨学科高难知识与推理题:不允许使用外部工具,测试模型自身知识和硬推理能力极限。这个领域里,Opus 4.7也还是领先。
当然,大家最卷的还是编程能力,其中最关键的一项就是真实GitHub软件工程任务,而这一项恰恰是Opus 4.7领先。对此OpenAI是不服气的。
OpenAI说Opus 4.7“过拟合了”,意思是它刷题了,所以这个分数不准,认为这一项有点作弊。至于其他指标,OpenAI并没有说,只是单独拎了这一项出来质疑。
Anthropic的应对:承认问题,同时放出Mythos信号

Anthropic面对压力也做了两件事。
第一件事:承认Claude Code质量问题
前一阵一直有报道说Claude Opus 4.6“降智”,出现brain fog这种脑雾现象,变笨了、变慢了、跑偏了、回复质量下降。很多人猜测,是它先把4.6降智,再推出一个可能比4.6稍微笨一点的4.7,让大家继续付钱。
这个事情已经有很多媒体,包括《财富》杂志,都报道过。之前Anthropic一直不理,反正就是“爱用不用,我还是最强的”。但在4月23日GPT-5.5发布之后,Anthropic发了事故调查报告,承认Claude Code里确实出现了质量问题,但否认了故意降低模型能力的指控。
它给了三个原因:
- 默认推理等级变更了,原来应该使用较高等级推理,现在默认用了较低等级。
- 缓存优化引入了一些程序漏洞。像这种系统一定有大量缓存,因为提示词进缓存之后更便宜、处理也更容易。
- 为了精简冗余输出内容,调整了一些系统提示词。
这三个原因共同导致了模型输出质量下降。现在它说问题已经修复了。也就是说,GPT-5.5不出来,它不承认;GPT-5.5一出来,它就承认了。
这让我想起苹果,经常有人说新手机一出,旧手机就变慢、续航就变差。苹果从来不承认,只会说它是为了更好地保护电池状态。Anthropic这次也算是又被抓住了一次。
第二件事:Mythos可能成为后手
它做的第二件事,是前面有个很强的模型叫Mythos。Anthropic说这个模型已经强到没朋友,不能直接放出来,只能先邀请合作伙伴使用,先找自己的漏洞。这消息之前就传出来了。
现在外界又开始讨论,Anthropic内部也并不觉得这有什么问题,甚至可能是在试探,要不要把Mythos放出来。因为Mythos比Opus 4.7还强。
这次GPT-5.5发布之后,有人拿Anthropic自己之前放出的测试数据和GPT-5.5对比,基本上算五五开,大概一半指标Mythos更高,一半是GPT-5.5更高,还有一些相等。
如果Anthropic被逼急了,真有可能直接把Mythos放出来。一旦放出来,影响可能非常大,因为这个模型特别擅长找漏洞,在网络安全领域属于专才。GPT-5.5在这一块未必有它强。如果Mythos真上线,我们现在跑的很多系统可能都要裸奔,这事是很吓人的。
国内模型集体活跃,DeepSeek V4成为焦点
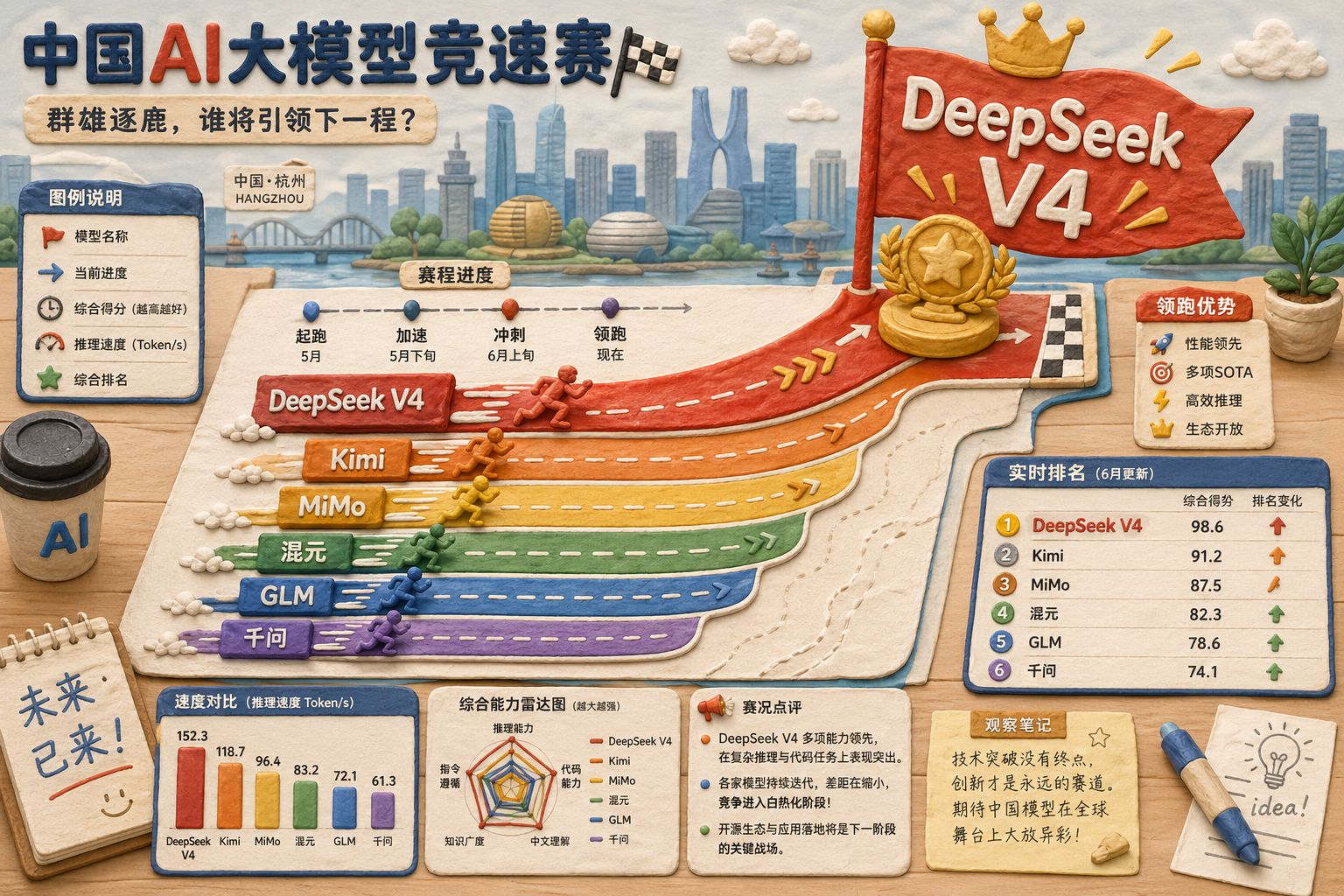
再说国内大模型,重点就是DeepSeek V4。其实国内这一周都很活跃,每天都在发新模型。除了DeepSeek V4,今天还有腾讯的混元3发布,这是尧舜禹从OpenAI被腾讯高薪挖回去后,待了几个月交出的第一份作业。不过在DeepSeek V4面前,混元3基本完全看不到,大家也不怎么讨论了。
这一周发布的模型包括Kimi K2.6、小米的MiMo V2.5 Pro、混元3,以及今天要讲的DeepSeek V4。Kimi K2.6我现在就在用,是个很好用的模型。MiMo V2.5 Pro发布时号称开源模型第一名,也就是比所有开源模型评分都高。混元3水平相对差一些,达不到国内一流,可能比MiniMax稍微强一点,但和GLM 5.1、千问3.6、Kimi 2.6相比还是有差距,更不用说和小米的MiMo V2.5比了。不过它也算四平八稳,能干活。
国内主要模型概况
- Kimi K2.6:1T参数量的MoE,激活32B,256K上下文,MIT许可商用,重点方向是长程编程、多模态和任务编排。
- MiMo V2.5 Pro:1T的MoE,100万Token上下文,重点是前端UI、dashboard等创意编程方向。
- 混元3:2950亿参数,激活21B,对标Kimi K2和DeepSeek V3,算是刚起步。
- DeepSeek:在许可证上最开放,直接使用Apache许可证,什么都不改,你们拿去用,爱干嘛干嘛。
Kimi 2.6的价格大概是每百万Token输出2.5到4美元。前两天很多人还在嘲笑MiniMax 2.7的开源许可证,说它要求商用必须先通知它。Kimi则是“你直接用就行”。而在这方面最开放的其实是DeepSeek,直接上Apache许可证。
这说明国内大模型竞争已经进入白热化。DeepSeek V4到底哪天登场,外人其实搞不清楚,但圈内人都清楚。中国这些大模型公司之间,包括中美大模型公司之间,真正做大模型的这几个人,要么是老同学,要么是老同事,谁家在干什么,大家大致都知道。所以大家都赶在DeepSeek V4之前把能发的先发了,不然光芒就全被盖住。
DeepSeek V4的真正意义:靴子终于落地

DeepSeek真正的位置是什么?它真的有那么强吗?现在已经有很多人出来吹了,但要讲清楚,DeepSeek V4真正的意义是“靴子落地了”。
原来很多人都在期待,觉得DeepSeek一发布,我们就彻底赢了,彻底翻身了,超英赶美,超过OpenAI、Anthropic、谷歌。就算不能彻底超过,也可以在价格上极大超越。
之前DeepSeek最火的时候,也就是R1发布时,它的能力并没有超越当时的GPT O1,只是特别便宜,用极致性价比达到了“将就能用”的状态,让中国人看到了希望:我虽然用不了你最好的那个,但我用这个稍微差一点的,也能解决问题。
今年春节之前我就讲过,全中国、甚至全世界都在等一件事:DeepSeek什么时候出V4,V4出来会不会震惊世界。结果春节没出,后来传3月初、3月末、4月初、4月中旬、5月初,各种说法都有,但基本都是拍脑袋瞎猜,没有具体依据。
大家为什么这么猜?就是因为大家都觉得,DeepSeek V4出来以后,会让整个中国模型扬眉吐气,会超英赶美。
但现在结果出来了,并没有发生这件事。靴子落地了,它发了。在极个别的两个指标上,确实达到了世界第一,这个是有的;价格上也的确是极致性价比,肯定比Anthropic、Gemini、OpenAI便宜很多,大概只有它们十分之一的价格。但大部分性能,其实也就是国内一线模型的水平,和GLM 5.1、Kimi 2.6基本持平。
关于华为芯片的现实情况
至于“使用华为芯片昇腾950”这件事,大家要注意,这种模型本身还是在英伟达芯片上训练出来的,最后为了适配华为芯片,可能还要做很多后期调试和调整。
它之所以拖到现在才发,可能就是为了去适配华为芯片。而所谓很强的昇腾950芯片,要到明年年底才能量产,现在能买到的可能还是910一类的芯片。
同时,美国商务部长卢特尼克已经说了,中国没有买任何一片H200,没有从英伟达直接买这种芯片。国内几个大厂,不管是字节、阿里还是腾讯,也都说已经向华为下了订单。那就别再神化了,继续往前走吧。DeepSeek也就可以把模型发出来了。
DeepSeek V4是一个开源模型,Apache许可证,所以它一定兼容英伟达。它只能说,在兼容英伟达的基础上,也保证能在华为芯片上跑得比较稳定,效能还可以接受。大家一定要理解清楚它和华为芯片的关系。
DeepSeek V4真正拿到世界第一的两项能力
那么DeepSeek V4到底哪两项达到了世界第一?
- Codeforces Elo:也就是竞赛编程排名系统分数。分数越高,排名越靠前。DeepSeek V4拿到了3206分,基本就是世界第一。这一项是程序员公认的硬核编程能力标尺,不是刷题库能刷出来的,确实是真刀真枪。
- LiveCodeBench:也就是竞赛编程连续评测,题目来自Codeforces、AtCoder和LeetCode等真实竞赛平台,长期跟踪,不是一锤子买卖。它测的是模型在连续多个竞赛项目上的综合表现。DeepSeek V4拿到了93.5%,意味着做10道题能做对9道以上。
所以在这两块上,DeepSeek V4确实是世界第一。
至于其他方面,就会稍微差一点。它自己也承认,在某些方面要比现在最顶尖的Opus 4.6、4.7差一些。现在在编程领域上,DeepSeek V4已经达到了Claude Sonnet 4.5的水平,也接近了Opus 4.6的非思考模式,但距离Opus 4.6思考模式以及Opus 4.7还是有差距。
为什么发布时主要提Opus,而没提GPT?
为什么它在发布时主要提Opus,没有提GPT?有三个原因:
- 前面OpenAI确实最强,这件事大家都公认。
- 之前Anthropic指责DeepSeek蒸馏,而OpenAI没说什么,没必要去点人家名字。
- GPT-5.5刚出来,只比它早几个小时,这种稿子不可能临时重写。
所以DeepSeek V4专门讲了,我们比最新的Opus 4.6 thinking模式和Opus 4.7还是有差距。
综合来说,现在各种评测、各种维度很多,在综合考量上,它有些指标甚至还没追上国内的GLM 5.1和Kimi K2.6,但有两个指标做到世界第一,也已经非常不容易了。只是它和最新的GPT-5.5相比,还是有不小差距,因为GPT-5.5比Opus 4.7还要更强一些。
“不诱于誉,不恐于诽,率道而行,锐然正己。”
这次梁文锋发布稿件的结尾,引用了荀子的四句话。翻成大白话就是:你们随便骂,我也不解释,我用产品说话。
所以,DeepSeek V4发布的真正意义,就是靴子终于落地了。不要再惦记着突然有个翻盘的救世主。就像打擂台一样,一个一个上去都被人打下来,然后说“我们还有个特别厉害的人没上来,等他上来给我报仇雪恨”。现在这个人也上来了,结果发现确实有优点,但总体还是有差距,大概就是这么个情况。
当前AI大模型竞争格局:两大梯队已经成型

现在整个AI大模型竞争,已经进入了一个新的格局,可以分成两大梯队。
第一梯队:OpenAI与Anthropic
第一梯队只有两家:OpenAI和Anthropic,遥遥领先,全方位领先。旗舰模型能力最强,在各种Harness Agent或者agency workbench里表现极强,生态也非常完整,商业化能力很强,而且没有太多包袱。
很多公司技术其实不差,但就是因为包袱太重、内部掣肘太厉害,追不上。这两家现在最强,能做长程任务、复杂工具调用、真实软件工程。当然,它们也比较贵。
第二梯队:中国厂商集体追赶
第二梯队是一批追赶中的中国厂商:GLM、Kimi、DeepSeek、MiMo、MiniMax、千问、混元。这些模型现在基本已经达到了日常编程任务和挂在Harness Agent下面“能用”的程度。
在某些日常工作里,单点能力已经够用了,而且价格极其便宜,基本只有美国模型的十分之一。
其他玩家的尴尬处境
至于没说到的那些,就相对比较尴尬。
- Grok:它在一些基础能力上可能比中国模型强,但在统合能力、编程等方面,未必比中国模型强到哪去,或者说即使强,用户也感受不出来。
- Muse Spark:也就是Meta最新出的、亚历山大·汪做出来的模型。它从开源转向闭源,到目前为止没有太多公开评测数据。它自己放出的一些数据,大概和混元3差不多,也许稍强一点,但应该也是泯然众生。
- Mistral:法国、也是欧洲最后的一根独苗。整个欧洲能做出模型的大概就是它们了,但现在做到什么程度,不太清楚。我个人感觉,它可能比中国模型还要再落后一点。
如果前面说的Grok、Muse Spark、Gemini这些模型都混到中国这个梯队里,那它们就危险了。为什么?因为中国模型开源,它们不开源;中国模型还便宜,价格只有它们十分之一。那它们就没有竞争能力了。所以这些模型必须冲进第一梯队,去和OpenAI、Anthropic竞争。
Gemini与谷歌:压力可能是最大的
再说Gemini。Gemini前面有一段时间很强,Gemini 3、Gemini 3.1,特别是Nano Banana 2,确实很强。我之前订阅Gemini,一个原因是Nano Banana 2,另一个是Notebook RM,这两个产品几乎无可替代。
至于它的模型本身,其实也就是“能用”,但一直没有特别惊艳。所以后来GPT出到5.4的时候,我就已经完全放弃使用Gemini模型了,通通转回GPT。
在发布GPT-5.5之前,Sam Altman专门拉着一堆中国面孔的小哥开发布会,发布GPT Image 2,这其实就像是釜底抽薪,把谷歌最底下那层梯子抽掉了。红色警报也就结束了。
所以Gemini现在的问题比较尴尬:它下周能不能出Gemini 4?就算出了,能不能超过GPT-5.5?如果出了还没Opus 4.7强,或者没GPT-5.5强,那发它干嘛?而且它现在连画图工具上的优势都没了,这就更麻烦。
还有一点,谷歌内部没有Claude Code或者Codex这样的工具。它收购了几个,也自己做了几个,但彼此掣肘,谁也没做起来。谷歌自己的创始人都说不行了,必须往前走。谷歌内部员工也在抱怨,说你不让我在公司里用Claude Code,又一定要我用自己的工具,但你自己又做不出来,这样我的编程效率反而下降很多。所以谷歌现在的压力非常大。
英伟达站台GPT-5.5,谷歌与Anthropic面临新压力

在这里面,谷歌的压力一定是最大的。现在它只能强调自己的芯片强,TPU很强。Anthropic也出来站台,说Claude Opus 4.7是用TPU训练出来的,也算是站了谷歌这边。
但你站了这个台,是有后果的。什么后果?就是这次GPT-5.5发布时,OpenAI干了一件特别绝的事情:速度没有降低。
这非常奇怪,因为绝大部分新模型出来都会变慢。模型规模变大,才会更聪明,而规模变大以后按理说一定会变慢。还有一个通常规律是,新模型一定会更贵。
GPT-5.5确实比GPT 5.4更贵,但为什么没有变慢?因为英伟达亲自站台,说GPT-5.5是在英伟达GB200 NVL72整套阵列上训练出来的,并且做了彻底优化。所以GPT-5.5的输出速度和GPT 5.4一样,每秒输出Token的速度没有变。这就非常强了。
虽然它更贵,但GPT-5.5解决同样问题时,消耗的Token会少很多,所以整体价格变化其实没那么大。这就是英伟达站台带来的效果。
Anthropic之前说自己是用谷歌训练的,那黄仁勋这种人是会记仇的,反手就给你来一巴掌:GPT-5.5就在我这儿,而且今天黄仁勋还给英伟达全员发信,要求大家都上Codex,因为这东西是在我们这儿训练出来的,是我们的亲儿子。
接下来就要看Anthropic怎么回击了,是不是会直接把Mythos拎出来,这很值得观察。还有就是谷歌下周到底能不能拿出一个让人惊艳的Gemini 4,我觉得可能性不大。就算拿出来,应该也不会特别惊艳。
而且现在真正竞争的是AI Agent或者agentic workbench这一块,谷歌和Grok在这方面都比较弱。Grok还在上蹿下跳,想买Cursor;谷歌在这块其实已经“买过一家”了,但买回来以后内部盘根错节,谁也发不上力,本来有些产品还不错,现在也都用不起来了。
普通用户到底该怎么选?GPT-5.5、Claude还是DeepSeek
最后回答一个问题:我们到底该用谁?是用DeepSeek,还是用GPT-5.5?
如果你不差钱
如果你不差钱,果断冲Anthropic的Claude Opus 4.7,加上Claude Code。它非常适合复杂工程、长程agent、企业级任务,目前这块还是做得最好的。
Codex加GPT-5.5虽然今天发布了,但还没有真正经过足够多实际任务的验证,还得再等一等。不过如果你不想被Anthropic平台完全绑定,也可以用Codex加GPT-5.5,我觉得是有机会赶上的。黄仁勋都发全员信了,说明这条线非常被看重。
使用Codex + GPT-5.5时的一个关键设置
但要注意一点,如果你上Codex加GPT-5.5,有一个配置一定要改。原来5.4默认使用快速模式,现在你要把它改成普通模式。
因为快速模式下,GPT 5.4会消耗1.5倍Token,你经常会发现用着用着额度就烧光了,而且GPT 5.4不允许改回去。但GPT-5.5是允许改回普通模式的。改回去以后,就按一倍速度烧Token,会省很多。
我现在用GPT-5.5,把它改成普通速度输出以后,感觉甚至比GPT 5.4还更耐用,而且它输出的Token更少,消耗也更低,这一点一定要注意。
如果你用OpenClaw
你直接用OpenClaw去挂GPT-5.5也没问题。我今天早上第一件事,就是打开Codex,下命令让它把我的OpenClaw小龙虾升级到最新版本,把本地Codex CLI也升级到最新版本,然后在OpenClaw里把GPT 5.4替换成GPT-5.5。
一个指令下去,这些就都升级好了。现在我在OpenClaw里已经可以直接用GPT-5.5了。
如果你预算有限
如果你还想再省点钱,也可以。像我这种预算比较紧的,就买国内模型的Token套餐。我现在用的是MiniMax M2.7的套餐,真的是便宜量大,虽然笨一点,但是量足。再配一个GPT Plus套餐兜底,GPT Plus是通过Codex挂到龙虾里去的。
现在我的正常任务用MiniMax就可以跑。如果你愿意,也可以换到GLM或者DeepSeek V4-Pro之类的模型,效果还会更好。所有非常难的任务,或者需要总结归纳的任务,遇到难题的时候,再专门切到GPT-5.5去做就可以了。
图像生成怎么选
要画图的话,一定要用GPT Image 2,那个东西是真的香,非常好使。我现在大量背景图和标题图都已经转到GPT Image 2了,这个一定要用。
我会不会转到DeepSeek V4?
至于DeepSeek V4,我会不会完全转过去?应该不会。因为DeepSeek V4估计会有很长一段时间算力紧张,华为芯片还没真正买回来,也还没交付。其他家,比如字节之类会不会部署它,还得再看。
如果字节部署了DeepSeek V4,我有可能去试一试。现在字节的code plan里我已经可以用GLM 5.1和Kimi K2.6了,我会更多地用Kimi K2.6。
至于DeepSeek V4那两个拿第一的项目,对我来说基本无感,因为我并不需要它去做编程竞赛这类任务,所以我未必会用它。等后面DeepSeek V4的算力宽松一些,我可能会测试一下。现在要用的模型太多,已经试不过来了。
总结

总结一下,GPT-5.5确实真香,但真正有价值的不是GPT-5.5本身,而是Codex,它才是OpenAI押注的超级App。
DeepSeek V4真正的作用,是让大家别再等什么救世主了,靴子已经落地,是骡子是马都拉出来了。它符合预期,但没有超出预期。
至于到底用哪个,还是要根据各自的预算情况、上网条件,以及你实际要解决的问题来决定。大概就是这样。