

OpenAI 和 Anthropic 的新模型将走向何方?
大家好,欢迎收听老范讲故事的 YouTube 频道。
OpenAI 的新模型有消息了。有媒体披露,一些内部信息泄露出来了。The Information 在 3 月 24 日发了报道,说 OpenAI 已经完成了下一代大模型的预训练,内部代号叫 Spud。山姆·奥特曼在内部对员工说,这是一个非常强的模型,并且可能切实推动经济加速发展。
随后,路透社、连线杂志、Bloomberg 都围绕着新一轮的组织调整,以及 Sora 关停等信息,对这个新模型进行了报道。OpenAI 正在把资源从视频等边缘业务抽回来,集中押注在代理、编码、企业产品和统一的超级 App 上面。
这里边,Spud 不是官宣名称,而是一个内部项目代号。所以我们通过这个词去猜它到底是什么意思,其实很难。OpenAI 的习惯是先随便起个名字,等到发布的时候,可能给它一个版本号。最后也许是 GPT-5.5、GPT-6,都是有可能的。
这次泄露出来的信息很少。OpenAI 内部把它描述为即将发布的新模型,内部预期是未来几周内,也有媒体描述为 coming weeks,就是几周后会发布。后面咱们也拍脑袋猜一下,这个模型到底会有什么新特色。
Anthropic 这边也泄露了一个新模型,叫 Mythos,也有人管它叫卡皮巴拉。这是因为人为错误泄露出来的模型。Anthropic 刚吹了牛,说自己的 code review 功能非常强,结果就出了这种 bug,实在不应该。
什么是 Code Review?

什么叫 code review?就是写完代码以后,我要去提交回去。不是说我从头到尾写一套新代码,而是说我要在原来的系统里稍微改点东西。
在这个时候,我们需要把所有代码都看一遍,看看你有没有改了一个错误,却带来十个新错误。这个过程就叫 code review。
它非常考验程序员对代码的理解能力,以及对大规模代码的处理能力。因为代码很多,把这段新代码放进去以后,你得知道它有没有牵一发动全身,是不是对其他地方有影响。所以真正的老程序员、资深程序员,是要去干这个活的。
Anthropic 说,自己出了一个新的 code review 功能,这个能力非常强。code review 完以后,再让程序员去看,99% 都是满意的,只有 1% 可能会有一点点小偏差。结果自己刚吹完这个牛,就出了这样的信息泄露 bug。
Mythos 是如何泄露出来的?

这个事情是 3 月 26 日《财富》杂志发现并进行了报道,3 月 27 日 Anthropic 就承认了,说确实有这么个事。这应该就是前面大家普遍猜测的卡皮巴拉模型。
大家注意,卡皮巴拉是内部代号,而 Mythos 是对外名字。因为如果不是对外名字,它也不会进到 CMS 系统里去。这次泄露,就是从 CMS 系统里泄露出来的。
CMS 是什么?
CMS 是什么?叫内容管理系统。名字听着很文绉绉,实际上就是官网后台。所有公司都会有官网,官网上有博客、有各种产品介绍、有成功案例。作为一个公司的官网来说,它就叫内容管理系统。
大家注意,这种管理系统上的东西会在什么时候写?比如说我今天发新模型,我会今天才写吗?肯定不会。一定会提前写,但也不会提前太多。比如提前一周、两周,把物料都准备好。准备完以后,先让它不可见,等新模型发布的时候,再统一拿出来,改一个参数说现在变成可见了。通常一定是这样的过程。
所以 Mythos 这个名字,一定是对外用的名字。因为对内用的名字,没必要写到信息管理系统里去。
为什么会被爬虫发现?
那它有可能发生什么样的配置错误,才会直接被人发现呢?这个以前我们也干过。当时盛大做电子书的时候,也是先写好文章,把网站都做好,但不能让别人发现,要等开完发布会以后才能拿出来。
如果后边我配错了什么东西,这些信息就会被爬虫拿走。虽然你可能没有一个公开链接,或者链接藏得很深,但爬虫不管这些,它会进来一顿爬,然后告诉大家有什么什么新东西了。
现在 Anthropic 的网站一定是大家每天都盯着的网站,一堆爬虫在那爬。所以它 CMS 系统里即将公开的信息被爬虫爬走了,然后就被像连线杂志、《财富》杂志这些媒体通通报道掉了。Anthropic 也只能自己承认,说确实有这个事。
猜测 OpenAI 的 Spud 会走向哪里?
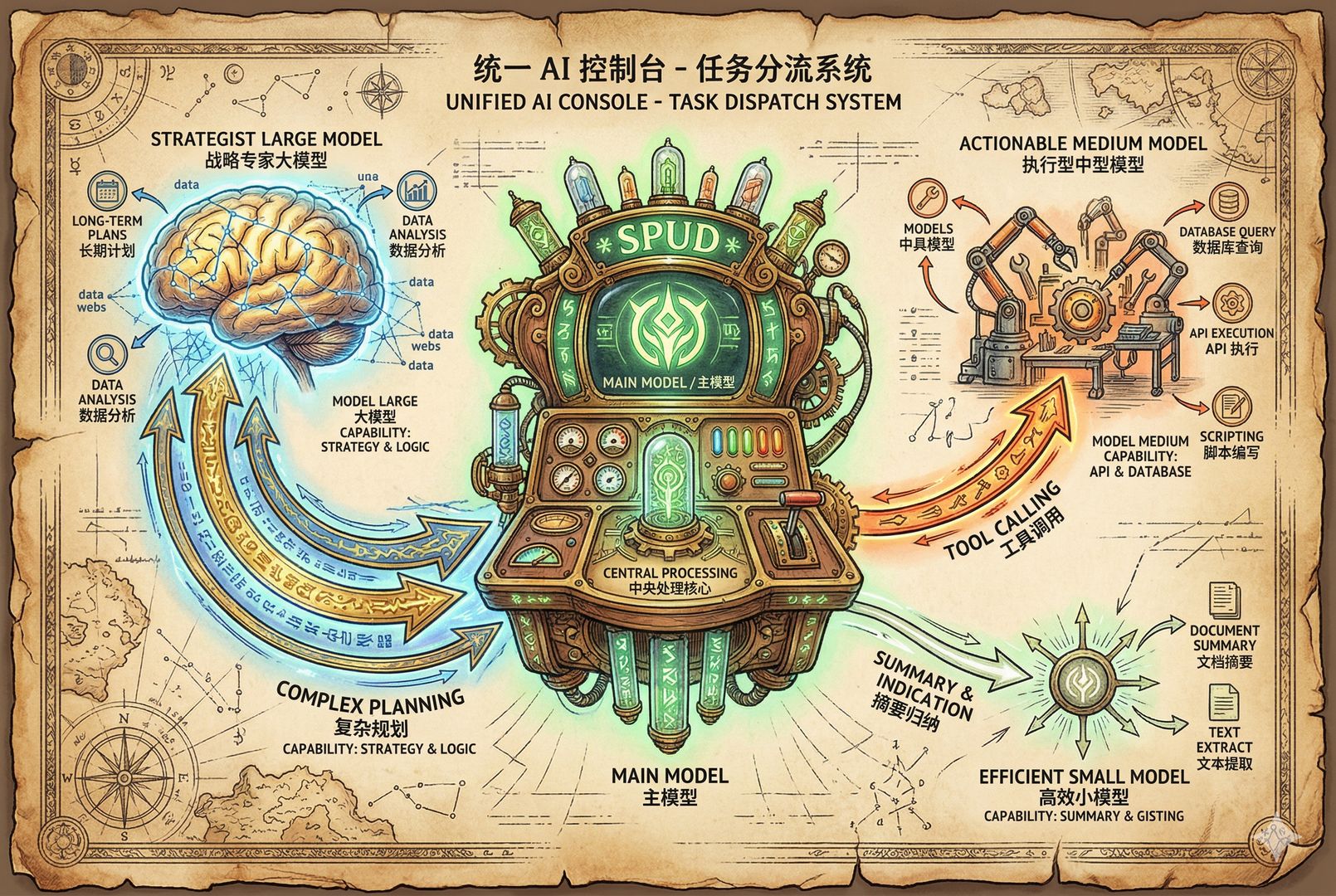
首先我们先来猜测一下 OpenAI 的 Spud 模型可能有什么能力。大家注意,这是猜测,猜错了就当听个笑话。
OpenAI 现在手里的真正大杀器是什么?是 OpenAI Codex。它把 OpenAI Codex 的创始人又拎回到自己公司里来上班了。真正需要做的事情是什么?就是要打造一款适合 OpenAI Codex 的模型。
一个“傻瓜型”统一入口模型
它需要一个什么样的模型?一个“傻瓜型”模型。不是说这模型本身笨,笨肯定没法用。怎么个“傻瓜法”呢?就是可以自动根据 agent 任务的复杂度,直接上不同算力和推理强度的模型。
比如说现在有 GPT-5.4、GPT-5.4 Pro、GPT-5.4 Mini、GPT-5.4 Nano 这些模型,那我到底什么时候该上 Nano,什么时候该上 Mini,什么时候该上 5.4,什么时候该上 5.4 Pro?这个东西如果用错了,不光浪费算力,它还慢。而且 OpenAI 去卖算力、卖套餐的时候,你的额度也是按模型分开的。
比如我使用 5.4 模型,第一个是很慢,第二个是我这 20 美金的套餐可能两三天就跑没了,然后就得等下个礼拜再回来,这谁也受不了。那你说我都挂 Mini 行不行?挂 Mini 的话,可能够它跑一个礼拜,但它又不够聪明,很多事情跑不对。
那怎么办?对于 OpenAI 来说,最简单的方式就是做一个统一入口。在这个入口里,它自己来分配:
- 复杂的任务,比如任务规划,上 5.4;
- 调用各种工具、跑一些简单任务,就上 5.4 Mini;
- 再简单一点的上 Nano;
- 最后把大量信息放在一起,需要总结归纳了,可能再上一次 5.4 Pro。
这样等于在需要聪明的时候就非常聪明,不需要聪明的时候又很省算力,反应也很快。
这应该就是 OpenAI 在干的事情。这种东西出来以后,OpenAI 就可以给出一个非常高使用额度的套餐。因为你大部分任务实际上都是简单任务,真正需要很大算力、很长推理的任务并没有那么多。
“自助餐”式套餐的类比

这相当于它出一个自助餐。我们现在使用套餐,其实就有点像自助餐,给你多少额度,至于你具体干什么,它其实不管你。
在自助餐里,比如我去吃日料,我就专盯着海胆或者鱼子这种比较贵的东西去吃,那任何日料店都受不了。
那他们怎么办?有的日料店就说,我给你限制一下,你只能吃两份海胆,只能吃几份鱼子。还有一些日料店是怎么处理的?我把品类变多。我这有海胆、有鱼子、有三文鱼、有北极贝,也有寿司、加州卷。寿司里头有米,加州卷里头米更多。
当我把这么一大堆东西都拿出来的时候,你东吃一口、西吃一口,最贵的食材,或者总体的食材消耗量,就下降了。
这个例子举出来,大家应该就理解了。OpenAI 想干的活,就是我给你准备非常非常多的东西。你想吃到什么的时候,我就给你相应的东西。
我给你准备一个非常齐全的菜单,大家根据各自需要,吃了些米饭、吃了些面条、吃了点三文鱼、吃了点鱼子、吃了点海胆,整顿吃下来,我还可以给你很便宜,因为你最后可能也就吃了一份海胆。这应该就是 OpenAI 的 Spud 可能努力的方向,当然这是我猜的。
Anthropic 的 Mythos 可能意味着什么?

下一个咱们讲一讲 Anthropic 这个叫 Mythos 的东西。我们从这个名字上,可以猜出来他们想干什么。原因很简单,因为这个名字是对外名字,就可以来猜了。
从 Haiku、Sonnet、Opus 到 Mythos
Anthropic 的这几个模型,第一个叫 Haiku,意思是俳句,是日本的一种极短诗体,传统上只有 17 个音节,通常分为 5-7-5 三段。
稍微大一点的模型,或者叫中等模型,叫 Sonnet,也就是十四行诗,也还不是很长。再往长一点的,叫 Opus。像我们现在用得最好的、跑“龙虾”的模型就是 Opus。它的意思是作品、剧作、篇章作品,是这样的一个名字,这个就可以写一本小说了。
最新这个即将发布的叫 Mythos,是什么意思?叫神话体系、神话叙事,一个文明的核心故事。大家就想明白这是个什么东西了吧。它不是 Opus 4.8 或者 Opus 5.0,它是在 Opus 的基础上再往前推进一档。这是比 Opus 更强一级的模型。
为什么 Anthropic 要做更强的模型?
Anthropic 为什么要做这样一个模型?首先我们要想,Anthropic 遇到了什么样的问题。现在的问题是 harness 太强,导致模型之间的差异被缩小了。
Harness 是现在比较新的一个概念,直接翻译过来可以理解为驾驭系统。Claude Code、Claude Copilot、OpenAI Codex,以及我们现在正在热炒的“小龙虾”、OpenClaw,实际上都属于这种驾驭系统。
这个词好像还有一个翻译叫马的缰绳。其实我觉得用“马的缰绳”来讲这个事,大家更容易理解。
我们现在有匹马,就是这个模型。你给它套上缰绳了,哪怕这个模型差一点,只要我这个缰绳控制得好,它也能够走直线,能把车拉走。一堆中国模型,在强力的“马缰绳”驱动下,也可以进到 Claude Code 或者 OpenAI Codex 这种 agent 系统里去,某种意义上滥竽充数。这就是 Anthropic 遇到的问题。
那么从 Opus 进化到 Mythos,从“作品”进化到“神话体系”,会有什么样的变化?就是把很多原来 harness 的能力内化到模型里边去。这就是他们要干的活。让新一代的 harness 只能适配新的、能力更强的模型,别人再想滥竽充数就充不了了。
Anthropic 不会弱化他们现在已经有的 harness,比如说 Claude Code,把它做得简单一些,它不会干这个活。但是它会让模型有更强的自主能力。
像原来说,这匹马是烈马,经常瞎跑,怎么办?我就把缰绳拉紧一点。以后 Anthropic 可能说,我给你更强的自主能力,你可以自己决定往哪走。这样的话,如果模型强,就可以更好地完成任务;如果模型差,那就没法看了。
咱们原来有两个成语,一个叫老马识途,一个叫信马由缰。你说我把缰绳松开了,你自己走吧。走的过程中,老马又认识路,它可能就把你带回家去了。Anthropic 如果把这个方向搞定,那些滥竽充数的中国模型大概率就会掉链子。
中国模型是如何“冒充” Claude 的?

中国模型到底是怎么冒充 Anthropic 的 Claude 模型的?
- 第一步最简单,就是 API 格式直接去模仿,这最容易。调用什么模型,命令以什么格式进去、什么格式出来,这块国内模型早就干了。所以现在我们使用比如 Kimi、MiniMax、豆包这些模型时,调 API 的时候,里头往往有两个接口:一个模拟 OpenAI,一个模拟 Anthropic。你在不同地方有不同接口可以调用。
- 第二件事就是蒸馏,这肯定少不了。现在国内的大模型都喜欢去蒸馏 Anthropic 的模型,一般不会去蒸馏 OpenAI 的模型。
AI 系统一般分哪三层?
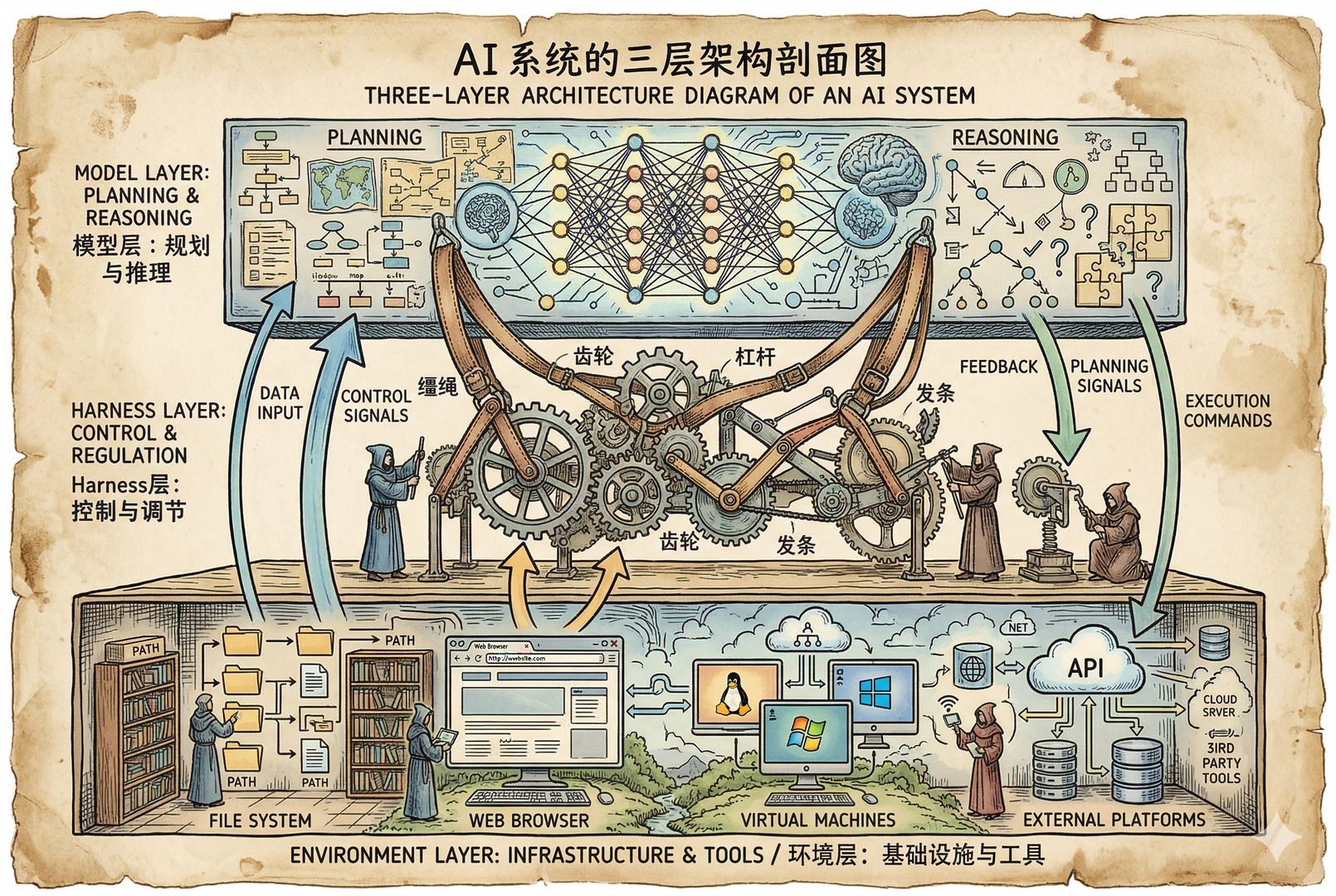
除了最简单的这两点之外,后边稍微讲一点点技术,尽量按简单方式讲。现在的 AI 系统一般分三层。
第一层:模型层
第一层是模型层,就是咱们讲的大模型。它负责什么?
- 长任务规划;
- 代码理解和生成;
- 工具选择;
- 多步推理;
- 目标保持;
- 自我修正;
- 在不完整信息下继续推进。
比如你说我要干一件什么事,它先想好第一步干什么、第二步干什么、第三步干什么,最后如何确认这个事情。
目标保持这个能力很难,也比较靠功夫。国内很多模型跑着跑着就跑偏了。然后是自我修正,跑偏了以后你能不能回来,这也靠模型能力。
还有一个很考验模型的,就是在不完整信息下继续推进。其实我们让模型去干活,给它的信息经常是不完整的。有的时候,我一个眼神你就领会了,这就叫不完整信息下的继续推进。有些模型则必须把话说得很透,它才能按要求往前走,这就是模型差异。
第二层:Harness 层
第二层就是 harness 层,叫驾驭系统层,或者叫“马缰绳层”。这里边它干的活包括:
- 代理循环;
- 上下文剪裁和注入;
- 子代理分工;
- 权限审查;
- 工具路由;
- 检查点、工作树、回滚;
- 记忆系统;
- 任务调度。
代理循环就是看看还有什么任务没做完,接着做;还没做完,再接着做,它会干这样的事情。
上下文剪裁和注入,就是把大量上下文保存起来、管理起来,在需要的时候,把正确的上下文剪裁好、压缩好,再塞到 agent 里去,让大模型去处理。
比较复杂的功能,比如检查点、工作树、回滚,这些也都是由 harness 控制。这些都属于编程里常用的东西。
检查点是什么?就是我在这设置一个点,如果出问题了,可以从这退回去。至于工作树,就是我们在同一个地方分叉,按不同方式去做,做完以后再合并回来。回滚就是哪做错了以后,可以 rollback 回到上一个状态,保证从那个地方继续往前走。
我们现在使用“小龙虾”,其实天天都在跟这些功能打交道。
第三层:环境层
最后一层叫环境层,包括文件系统、脚本执行、浏览器、图形界面、虚拟机沙箱,或者 GitHub、Slack、Discord、Telegram、QQ 这些外部系统。整个 AI 系统,基本上就是这三层在工作。
哪些能力可以靠 Harness 补齐?
有些模型能力差一些,是可以靠 harness 来补齐的。比如我现在“龙虾”里用的是 MiniMax 2.7,因为“龙虾”自己能力还是比较强的,所以基本上能干活。
哪些能力可以补齐?
- 明确任务解析;
- 代码库检索;
- 文件修改;
- 各种脚本执行;
- 固定格式输出;
- 规则驱动审批;
- 记忆回填;
- 向量搜索。
相当于什么呢?一个眼神过去它搞不定,但我掰开了揉碎了,把事情讲清楚,那么 MiniMax 也能干活。
为什么这些就可以搞定?因为它们是通过子代理模板、预设工具链、各种 agent 描述文件、权限模式、沙箱这些东西,等于“龙虾”限制了模型跑偏。这些模型相当于是烈马,有一个很强的缰绳,就可以把事情往前推。
哪些能力不容易靠 Harness 补齐?
(img: 一匹烈马与一匹老马并列前行,前者被紧紧拉住缰绳仍试图偏离道路,后者在雾气、岔路和噪声中依旧稳稳朝目标前进,象征难以外部补齐的模型本体能力,羊皮纸,钢笔彩色手绘的统一风格。3:2 )
还有一些能力,是不太容易被 harness 补齐的。这些能力,是真正吃模型本体的。
- 目标在很长上下文里不漂移;
- 面对噪声和歧义的时候继续推进;
- 知道什么时候该停,什么时候该问,什么时候该反思;
- 工具选择是否正确合理;
- 信息不完整的情况下,如何高质量地自我纠偏。
比如我给你讲半天,你一定要记住你到底要干什么,不能讲了半天以后你忘了,这不行。这个中国模型就比较容易出问题。
第二个,是面对噪声和歧义的时候继续推进。比如我给你开个玩笑,我给你阴阳怪气一下,你要继续沿着正确路径往前走,不要被我带偏了。
还有什么时候该停,什么时候该问,什么时候该反思,这也非常考验模型能力。像我现在使用 MiniMax,就必须告诉它:这个事该停下来了,这个事你别问我,你自己去搞定,那个事你现在要做一次完整的自我反思。我只能手动做这件事,没法让它自动做。
以及工具选择是否正确合理。你使用 Opus、使用 Claude 的模型,它就会比较合理地去使用工具。包括我用 GPT-5.4,在这块也没什么问题。但你使用中国模型的话,就会出现一些跑偏的情况。你要不停地去校正它,校正完了以后还要告诉它,记住,这个东西下次不能再错了。当然有时候它还会再错一两次,但你多让它记几次以后,它还是能记住的。
还有就是信息不完整的情况下,如何高质量地自我纠偏,这也非常非常考验模型能力。
Mythos 的升级重点可能在哪里?
这一次 Mythos 的升级,主要就是照着刚才我们讲的这些 harness 比较难补齐的部分去升级。Anthropic 讲了,说他们主要会在网络安全能力、计划能力以及错误修复能力上进行升级。这是在媒体报道了 Mythos 这个名字以后,Anthropic 自己承认的。
同一个 harness 使用 Mythos,可能会比今天的 Opus 4.6 更进一步。比如更少跑偏,更少问一些错误的问题,更少在多步链路里丢失目标,更会使用计算机,更能够在复杂系统里自我修正。这就是他们想去做的事情。
中国模型可能就要抓瞎了,可能会在高噪声环境下没法稳定地完成完整任务。
遇到这种比较差的马,你就一定要把缰绳拉紧。在低监督环境下,它自我推进的能力肯定也会变得很差。特别是像网络安全,因为网络安全里一定是信息不完整的,而且很多人惦记骗你。你怎么能够在这个时候把事情做对,这非常考验模型。它如何进行比较长距离的规划,如何进行错误修复,这些都会很考验模型。
未来会如何发展?

第一个,几周之内,咱们应该会看到两个新模型。不管是 OpenAI 还是 Anthropic,都会推出新模型。我个人会更期待 OpenAI 的模型,因为我订阅了,我花钱了。
Anthropic 我一直没舍得。正确使用 Anthropic 模型的方式,应该是这样:
- 先花 20 美金订阅;
- 老老实实在稳定的 IP 环境下使用;
- 尽量在 Claude Code、在 Anthropic 自家的工具里用;
- 用一段时间以后,再逐渐地到“龙虾”里去用;
- 养一段时间号以后,再看看是不是让它在这种比较复杂的 IP 环境下工作,才能避免封号。
否则的话,它封你没商量。
像我现在其实可以基本保证稳定 IP,因为基本都在家,也不怎么出门,不会遇到 IP 经常跳来跳去的情况。但是养号这段时间,我肯定还是要花美金去订它的账号,而且在这段时间里,我是没法高强度使用它的,所以我一直没舍得。
那么 OpenAI 推出新模型以后,我大概率可以在 OpenAI Codex 里靠 20 美金套餐,就基本让它跑完,而不会像现在这样,跑个两三天就把一周额度跑光。如果真能做到这一步的话,我应该还是比较开心的。
OpenAI Codex 其实是一个设想非常宏大的产品,就是它功能未必都实现得那么好,但它设想的功能很宏大,而且对于各种模型还是相对比较友好的。
至于 Anthropic 的 Mythos,反正我现在准备等中国模型去蒸馏它。我相信这些公司应该不会放过它。等这些模型把 Mythos 的能力蒸馏回来以后,我应该也能够使用部分 Anthropic 的能力。
好,今天的故事讲到这里。感谢大家收听。请帮忙点赞、点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
背景图片
Prompt:in the style of modern editorial watercolor, ink wash edges, soft bloom, textured paper feel, restrained palette, clean hierarchy, hyper-detailed Silicon Valley startup office interior, floor-to-ceiling glass walls revealing a garden of blooming cherry blossom trees, employees working at sleek standing desks with curved monitors, soft golden hour light casting gentle shadows, blush pink and warm ivory tones, indoor plants mixed with the view of outdoor樱花, depth of field with foreground cherry petals, warm and orderly atmosphere –no cluttered, –ar 16:9 –stylize 600 –chaos 15 –v 7.0 –p qaczhqj



