
DeepSeek V4 终于开始了属于它的革命,只是方法可能出乎了很多人的意料。
革命不是发生在发布当天
DeepSeek 发布之后,很多人的第一反应是:就这?跑分没有炸裂,发布会没有高潮,实际上压根就没有发布会。梁文锋也没有站出来讲一个“AGI 改变世界”的宏大故事,什么都没有。
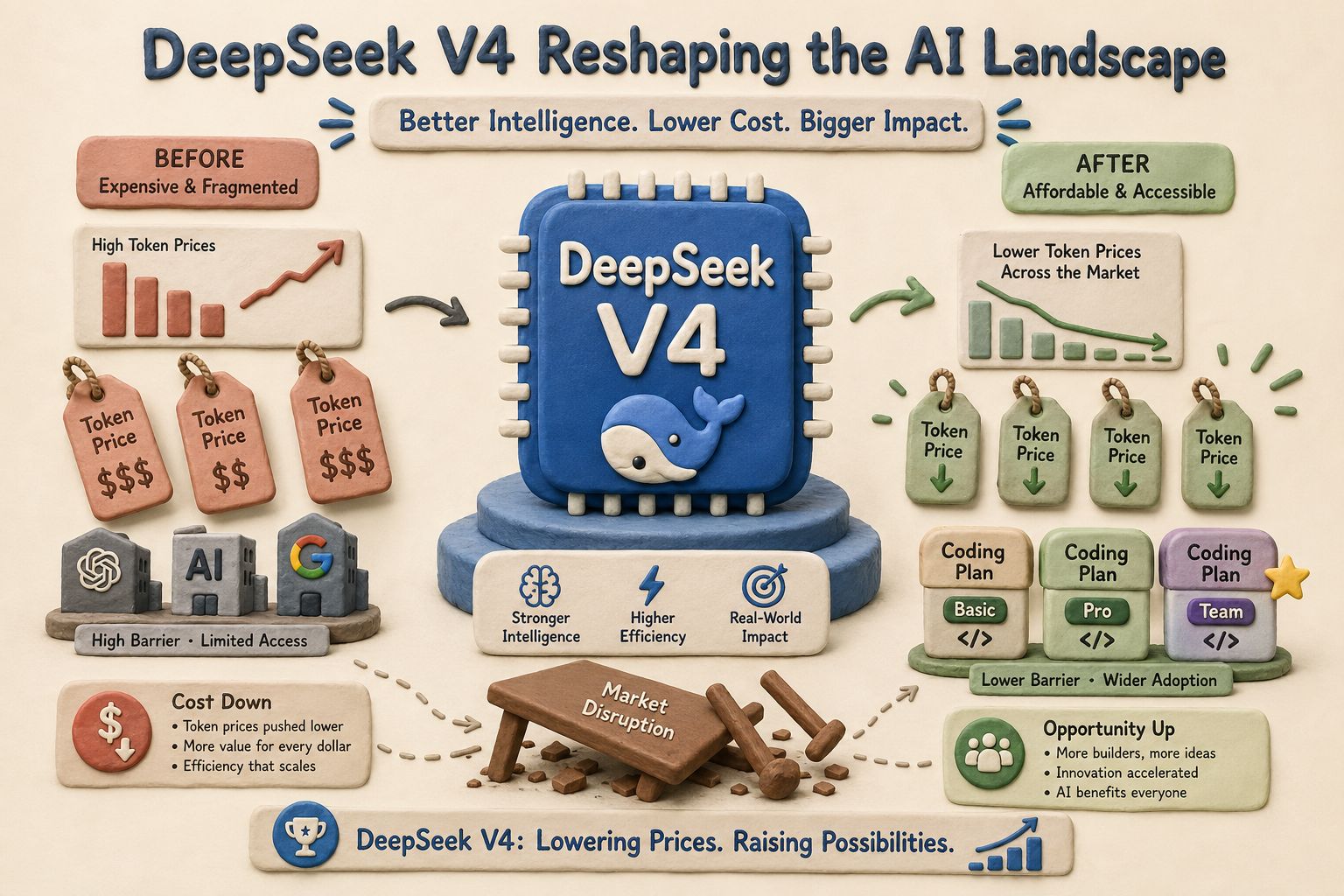
但是几天之后,真正可怕的事情发生了。DeepSeek 没有推出什么 Coding Plan 或者 Token Plan,也没有把用户锁在一个订阅套餐里,而是直接掀桌子:连续降价。

这件事情的意义可能比跑分更大。因为它不是在说“我的模型比你强一点”,而是在说:你们靠高 Token 价格,再用 Coding Plan 去捆绑用户的玩法已经结束了。
所以 DeepSeek 这一次的降价,其实是在给现在的 Coding Plan、Token Plan 泼冷水,直接说你们就是在坑人,咱这个才是实在人。
DeepSeek V4 发布后的微妙气氛
DeepSeek V4 发布以后,气氛有一点小诡异。原因很简单:期望越高,失望越大。大家期待的全面碾压、各种追平、国产算力全面验证、多模态、agent、coding 一起爆发,都没有来。
跑分当然还是可以看的,但是没有出现去年 R1 发布时那种核爆级的震撼。所谓 R1 核爆级的震撼,最核心的也不是说它真的碾压、追平了,而是它特别便宜,便宜得简直没法看。
这一次 DeepSeek V4 发布时,价格其实跟国内主流模型差不太多,各有长短。有些地方 DeepSeek 还稍微贵一点,有些地方它比别人稍微便宜一点,但便宜得也不是很多。
DeepSeek V4 Pro 是一个很强的模型,特别是在代码、数学、agentic coding、长上下文方面。但它不是那种一眼看上去就把所有模型都打穿的东西。所以第一波舆论里,大家想尬吹它,因为准备了很久,却不知道从哪下嘴。
梁文锋也没有出来讲故事,反而有点像是在说:你想骂就骂吧。最后写了四句:
不诱于誉,不恐于诽,率道而行,端然正己。

最后大家找不到夸的了,就开始吹 DeepSeek 从来不加班。别的大模型公司都是各种加班、各种卷,DeepSeek 到下班就让大家回家。虽然不加班是一件很棒的事情,但是在发大模型的时候说“模型做得可能不重要,但是它不加班”,吹起来就有点尬。
DeepSeek 自己也说了,现在降价了,但等到华为昇腾 950 上来以后,还会再降价,比现在还便宜。不过那至少要到今年下半年或者明年才有可能出来,大家还可以继续拭目以待。
贡献者名单和体感测试
还有人开始吹贡献者名单:里面居然把离职的人也都标注出来了。有人猜梁文锋是不是压力山大,或者有些委屈,想要吐槽一下。因为很多大厂都在挖他的人,比如罗福莉,还有一些去了字节、腾讯的人,都给标上了,也标明他们在哪个模型里做出过贡献。
- 有人做过 R1;
- 有人做过 V3;
- 罗福莉做过 V2;
- 还有人做了 DeepSeek OCR 模型。
这些人的名字前面画了星号。
实际上这种方式在国外很常见。国外大厂发软件时,会把即使已经离职的员工也标在上面;发论文时,也会把已经离职的员工或者贡献者标上去。但在国内比较少见,国内通常是领导标前面,离职了基本就没有名字。所以把离职员工标在上面,在国外算惯例,在国内是比较罕见的现象。
因此也没必要特别过度解读。梁文锋把他们标出来,并不是惦记着羞辱谁,或者跟大家诉苦。
现在还有一些人开始做体感测试。因为跑分这件事,跟我们的体感是不一样的。有人拿它去写网站,或者去写小红书,跟 GRM、Opus 和其他模型比较,结论是 DeepSeek V4 在体感上还是相当不错的。
但是体感很主观。我觉得好,你觉得不好,这都正常。所以有人录体感测试视频,或者写文章继续吹捧 DeepSeek V4。大家都吹成这样了,老范自己也去用了一下,下面会讲讲体验。
真正的革命:连续降价
这一次,作为一个国运级产品,DeepSeek 真正开始革命并不是在它发布的那一天,而是在发布之后。DeepSeek 进行了连续降价,每过几天就降一次,价格一下把其他模型,包括这些 Coding Plan、Token Plan,全打穿了。
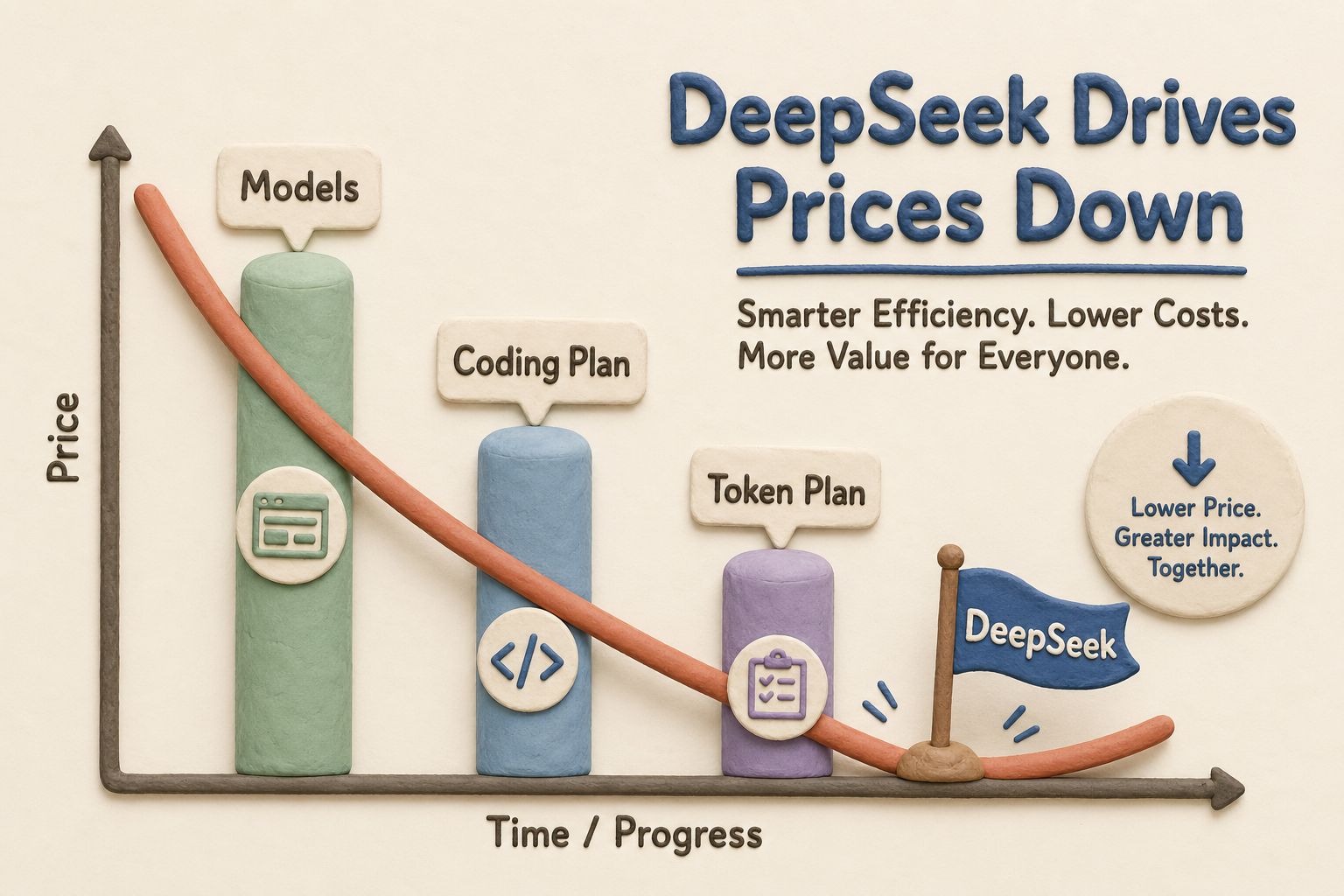
当前价格
现在的价格大致是这样的:
- DeepSeek V4 Flash:输入 100 万 Token 的价格是 1 元;如果命中缓存,100 万 Token 是 2 分钱。
- DeepSeek V4 Pro:输入 100 万 Token 的价格是 3 元;如果命中缓存,100 万 Token 是 2 分 5。
这个价格非常便宜。尤其是 Pro 的价格,2 分 5 就可以把信息输进去。
官方同时说明,全系列模型输入缓存命中的价格都已经降到了首发价格的 1/10。该价格调整自北京时间 2026 年 4 月 26 日 20 点 15 分生效。当前 DeepSeek V4 Pro 模型是 2.5 折的价格,非常便宜,优惠期延长到 2026 年 5 月 31 日 23 点 59 分。也就是说,一直到 5 月底,都可以使用这个 2.5 折价格。
这个价格可以说已经让 Token 价格无感了,随便用,感觉像没花钱一样。而且 DeepSeek 还说,等到昇腾 950 到线、到货以后,还会继续打折,大家可以稍微期待一下。
按 100 万 Token 粗算
按照 100 万 Token 粗算,Flash 能有多便宜?假设一个 Agent 任务是 80 万 Token 输入、20 万 Token 输出,总计 100 万 Token。
- 使用 V4 Flash,输入成本是 8 毛钱;
- 输出成本是 4 毛钱;
- 合计 1 块 2,还没有计算缓存。
这个价格已经非常便宜了。
那 100 万 Token 的上下文到底有多少?很多。一本《鹿鼎记》大概总共是 200 万到 300 万字。
一次实际使用体验
老范自己试了一次,把 DeepSeek V4 Pro 和 DeepSeek V4 Flash 挂到了 Claude Code 里。改配置文件就可以:默认模型是 DeepSeek V4 Pro,Opus 模型是 DeepSeek V4 Pro,Sonnet 模型是 DeepSeek V4 Pro;如果需要使用 Haiku 模型,也就是 Anthropic 自己那个特别小的模型,就调用 DeepSeek V4 Flash;如果要开 subagent,也就是子代理,也使用 DeepSeek V4 Flash。然后按照 Max 模式疯狂跑。
这次让它做的事情是:现在有很多人在 GitHub 上分享 GPT-image-2 的提示词,比如画什么样的图应该用什么样的提示词,建立了一个大仓库来存放这些内容。于是就让它把这个仓库拉下来,建一个本地网站,可以搜索、查找这些提示词。
一句话扔进去,它就开始干,基本上干完了,过程中没有什么错误,直接把网站做出来。

总共花了大概 8 毛多钱。其中 6 毛多钱是 Pro 的价格,1 毛多钱是 Flash。Flash 的缓存命中率是 0,全都是按新输入来算;Pro 的缓存命中率是 98.7%。
为什么会有这么高的缓存命中率?原因很简单:在写一个代码项目时,它会反复把这个项目的代码输入、输出,所以缓存命中率非常高。在这样的情况下,总共大概花了 8 毛多钱,就得到了一个网站。
这也是为什么说,使用 DeepSeek 写网站时,Token 价格基本无感。花 8 毛多钱写出一个网站,而如果用 Codex 或者豆包 40 块钱的 Coding Plan,5 个小时额度可能就用完了。在 DeepSeek 这里,8 毛钱搞定。就算现在 2.5 折以后变成 2 块钱搞定,也依然可以接受,仍然是无感的。
为什么降价就是革命
有人可能会说,这不就是降价吗?怎么就革命了?真不是大惊小怪。
现在各个云厂商也好,AI 厂商也好,玩的游戏是:把 Token 价格定得很贵,也不降价。前面小米的卢伟冰还出来讲,说 Token 很贵,不可能降价,成本就在这里。然后你可以来买我的 Token Plan,或者买我的 Coding Plan。
Coding Plan 和 Token Plan 的区别
为什么有的叫 Token Plan,有的叫 Coding Plan?区别主要在于:
- Coding Plan 通常只能编程;
- Token Plan 通常会包含 STT、TTS、画图、搜索、embedding、RAG 等能力;
- STT 是语音转文字;
- TTS 是文字转语音;
- 如果是 Coding Plan,除了编程之外,其他能力往往不让用,还要再买其他 Token 才能使用。
这些 AI 厂商和云厂商,希望大家尽可能订 Coding Plan。订完 Coding Plan,你就相当于被绑在它的平台上了。
大家都买 Coding Plan 的结果,就像大家去吃自助餐。有的人吃得多,有的人吃得少,平均下来商家肯定能挣钱。

比如很多自助餐厅都有生日免费。你生日免费了,不能一个人去吃,肯定会带一帮人去。这里面有人吃得多,有人吃得少,而且也不可能每次都照死了吃,绝大部分人的食量还是有限的。所以自助餐厅就能挣到比较多的钱。
另外,这些云计算厂商和 AI 厂商都有很完整的服务体系:视频生成、图片生成、语音生成、数据库以及各种其他业务。只要你买了它的 Coding Plan,它就相当于把你绑在这里了,你不能再去买别人的,必须在它这里来。
但是现在 DeepSeek 一下把桌子掀了。它说:你看,我现在写个网站,你们那边可能 5 个小时额度跑光了,在我这里几毛钱、不到一块钱就写好了。这个价格,还要什么自助餐?还要什么自行车?
Coding Plan 玩家开始难受了
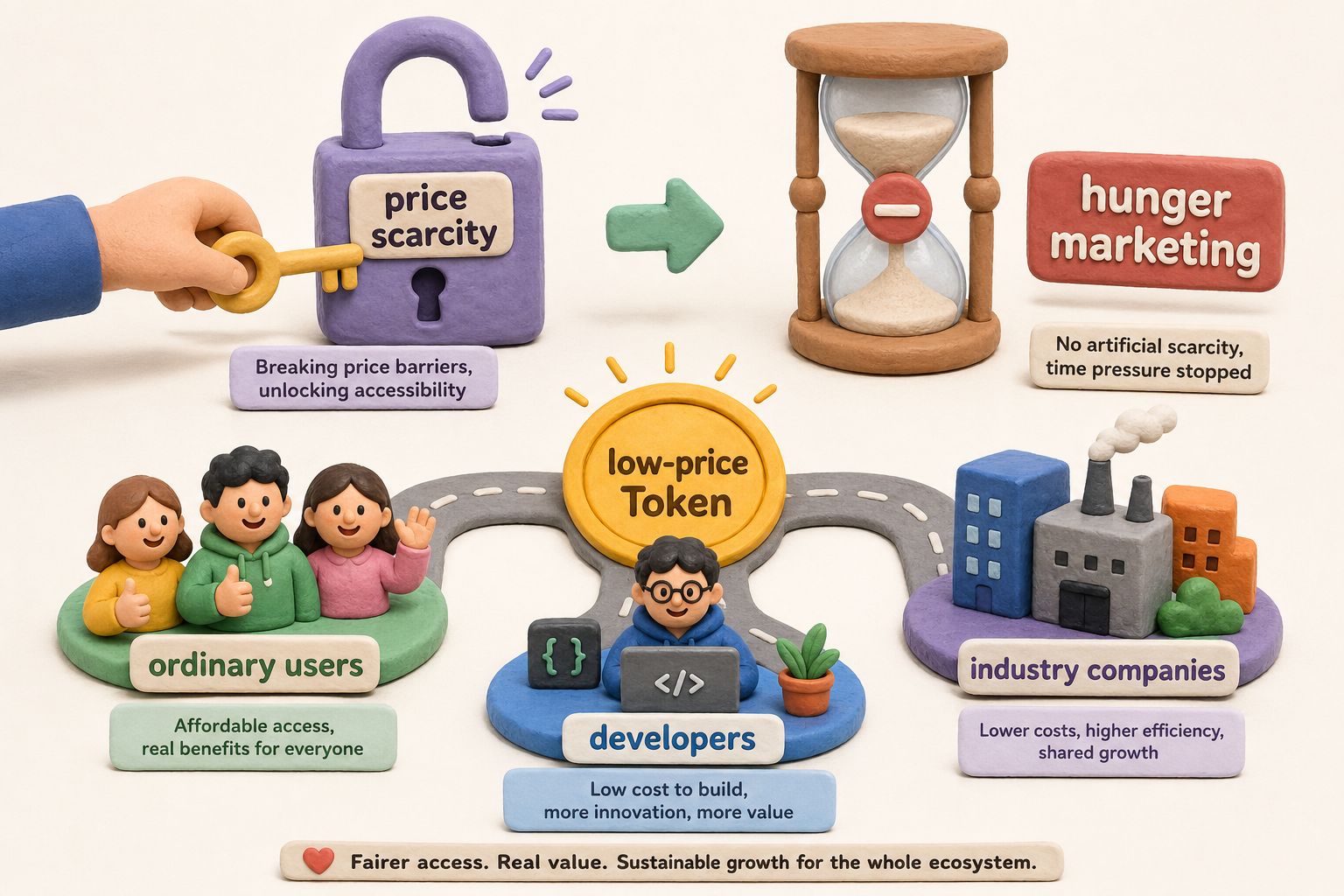
这样一来,做 Coding Plan 的人日子就不好过了。前面不但大家搞 Coding Plan,还给 Coding Plan 搞饥饿营销。
- 智谱的 Coding Plan 买不着,每天早上 10 点要排队、要抢,还经常抢不到。
- 阿里 40 多块钱的 Coding Plan 直接取消了,必须买 200 块钱的,而 200 块钱的还经常买不着,经常下架。
- 字节的豆包 Coding Plan 也玩这个:买的时候突然告诉你,最便宜的 40 块钱下架了,必须买 200 的。
现在用户可以说:我不用了,直接吃多少付多少,直接用 DeepSeek,不需要这些 Coding Plan。

那前面喊着“这个价格很贵”的罗福莉怎么办?一拍脑袋,开源吧。现在把小米的 MIMO 2.5 全系模型通通开源,而且直接上 MIT 协议:不做任何修改,大家随便用,愿意商用就商用。反正已经赔本了,后边就只赚吆喝。
其他这些人,比如智谱、阿里、Minimax、Kimi,现在就头疼了,估计正在连夜开会,讨论怎么调整价格策略。前面把菜标得很贵,逼着大家吃自助,现在被人把桌子掀了,人家直接亮底牌:这东西其实很便宜,大家直接在我这里买就可以,不需要买自助餐了。
Flash 和 Pro 到底怎么选
很多人会说,Flash 很便宜,Pro 其实还是挺贵。现在 2.5 折便宜了,但 5 月 31 号以后是不是就变贵了?
第一,5 月 31 号以后未必会变贵;第二,到下半年没准昇腾 950PR 上来以后,它又打折了。在中国,只有降价的,没有涨上去的,涨上去这件事很难。前面各个模型公司刚想涨价,想涨 Token,想涨 Token Plan,马上就被打回原形了。
Flash 够用的场景
Flash 这个模型,日常写代码很够用。因为代码需要的知识相对比较少,改 bug、写前端、写脚本,用 Flash 模型没有太大问题。
长上下文做一些理解,Flash 的性价比也很高。DeepSeek V4 Pro 的上下文是 100 万 Token,Flash 也是 100 万 Token。别看它便宜,它也有 100 万 Token 的上下文。做一些数学、代码竞赛,Flash 其实也够。
必须上 Pro 的场景
那什么时候 Flash 不行,必须上 Pro?
- 复杂 agent 的多轮规划;
- 需要规划很多事情,并进行多次 function call,也就是调用外部工具;
- 基于事实核查的任务;
- 财经研究;
- 节目脚本等需要更强底层知识和判断力的内容。
Flash 和 Pro 之间最主要的差距,是底层知识库大小。Flash 的底层知识库小一些,但运算能力其实不差,而且算得很快。
所以现在使用龙虾、爱马仕,包括 Claude Code 这种 harness agentic,Flash 基本上都是够用的,不需要上那么多 Pro。正常配置就是:Flash 负责跑量,Pro 负责兜底。特别难的、比较难判断的、需要长程规划的任务,用 Pro;正常工作通通用 Flash,这样就会非常便宜。

Token Plan 和 Coding Plan 的逻辑被打穿
随着 DeepSeek 的降价,Token Plan 和 Coding Plan 的逻辑就被彻底打穿了。绝大部分普通人根本不需要订阅,直接用 DeepSeek V4 的便宜 Token 就够了。低频用户可能每个月养虾的钱也就是几块钱,或者十来块钱,比买 40 块钱的最低套餐便宜很多。
AI 厂商为了不让你买最便宜的套餐,会给 40 块钱的套餐起名叫 Lite,就是告诉你,这只是让你尝鲜的。真正干活,还要买 Pro,买更贵的套餐,至少 200 人民币以上,而且还直接下架这些最便宜的套餐。
DeepSeek 为什么敢这么做
DeepSeek 跟这些大厂不一样。DeepSeek 自己没有电商,没有社交,没有短视频,没有云计算,也没有手机、汽车、办公套件、操作系统、浏览器、大规模企业 SaaS,这些它全都没有。
阿里、字节、腾讯有这些东西,所以它们尽可能希望把你绑在平台上,不要出去。
一旦你买了它们的 Coding 套餐,或者 Token 套餐,这种东西是有排他性的。就像吃自助餐,不可能在这家吃完自助餐以后,出去再吃碗面。自助餐的意思是,你一定要在它家吃饱,绝对不能再出去吃任何其他人的。
DeepSeek 除了没有这些生态之外,还缺很多东西:STT、TTS、绘图、视频生成、音乐生成、Embedding、Rerank,它通通都没有。它只有一个文本模型,其他全都没有。
所以 DeepSeek 的竞争方式就是:我的文本模型最便宜,你们就在我这里用。用完以后,如果你需要 TTS、STT,或者需要绘图,爱调谁的就调谁的,我不管。
这就像它卖的面特别便宜,你在它这里吃完一碗面以后,出门再去吃俩包子,它也不管。这跟自助餐完全是不同的逻辑。所以 DeepSeek 根本不需要锁死用户。

再看 OpenAI、Anthropic、小米、字节、阿里,它们都是希望锁死用户:你只要来我这里,就别出门了,在我这一家全部吃完。这是很大的差异。
开源模型与默认入口之争
还有一点很重要:DeepSeek V4 是一个开源模型,彻底开源。其他云计算厂商去薅它羊毛是必然的,也就是自己部署 DeepSeek V4,对外提供服务。
与其让别人分流,不如 DeepSeek 直接给一个低价。你们自己掂量掂量,上了 DeepSeek V4 以后,到底能不能出我这个价格。出不来,会被人戳脊梁骨;如果出得来,还划不划算?不那么划算。这样就让用户尽量沉淀在 DeepSeek 这里。
DeepSeek V4 其实是在抢这些 agent 的默认模型入口。单纯聊天或者做其他事情,缓存命中率可能没那么高;但越是跑 agent,比如养龙虾、养爱马仕这种东西,缓存命中率就越高,使用成本就越低。
普通用户每天使用龙虾、爱马仕,可能也花不了几十万 Token。在这种情况下,一天成本可能就是几毛钱,或者一块钱左右。所以为什么还要去买那种 Coding Plan 呢?
Coding Plan 仍然有适用人群
那 Coding Plan 是不是在某些情况下还是会比 DeepSeek V4 便宜?会。
这就跟吃自助餐一样。如果大胃王都吃不回本,那自助餐就倒闭了,没有人会进去吃。这个价格一定会让很多人觉得自己能吃回本。大家抱着这样的心态进去以后,自助餐厅老板才能挣得盆满钵满。
所以如果有些“大胃王”确实特别能吃,买 Coding Plan、Token Plan 也还是划算的。但是如果进来吃饭的都是大胃王,开自助餐的老板就该哭了。卖 Coding Plan 的人如果发现每个人都卡边掐沿地把所有 Token 消耗完,那就有点太过分了。
甚至有人可以这样做:买一个 Lite 套餐,一个月 40 块钱,先把它烧完,然后再接着跑 DeepSeek。这个肯定是所有自助餐厅老板都不欢迎的食客。
总结:DeepSeek V4 革命的是定价
DeepSeek R1 出来的时候,我就说这东西是国运级的,现在它依然是国运级的。作为国运级产品,降价到底会带来什么改变?低用量客户的 Token 基本无感了。我们随便养个龙虾,挂个 Claude Code,基本不会有任何感觉。
价格稀缺性被打破,饥饿营销失效,这真的会给整个行业带来改变。什么叫国运级?就是带着整个国家,甚至带着整个世界一起发生改变的产品,才叫国运级产品。
所以这一次 DeepSeek V4 革命的地方不是跑分,不是它做了别人做不了的事情,而是定价。它通过定价改变了整个商业格局。DeepSeek V4 最开始看跑分不够炸裂,但是价格上来以后,全行业的人现在都是晕头转向,不知道该怎么办。
希望 DeepSeek 可以带来更多惊喜。感谢大家收听,请帮忙点赞,点小铃铛,参加 Discord 讨论群,也欢迎有兴趣、有能力的朋友加入付费频道。再见。
背景图片
