程序员的天真的塌了吗?马斯克说AI编程也要玩端到端了,直接生成优化过的二进制代码。
大家好,欢迎收听老范讲故事的YouTube频道。
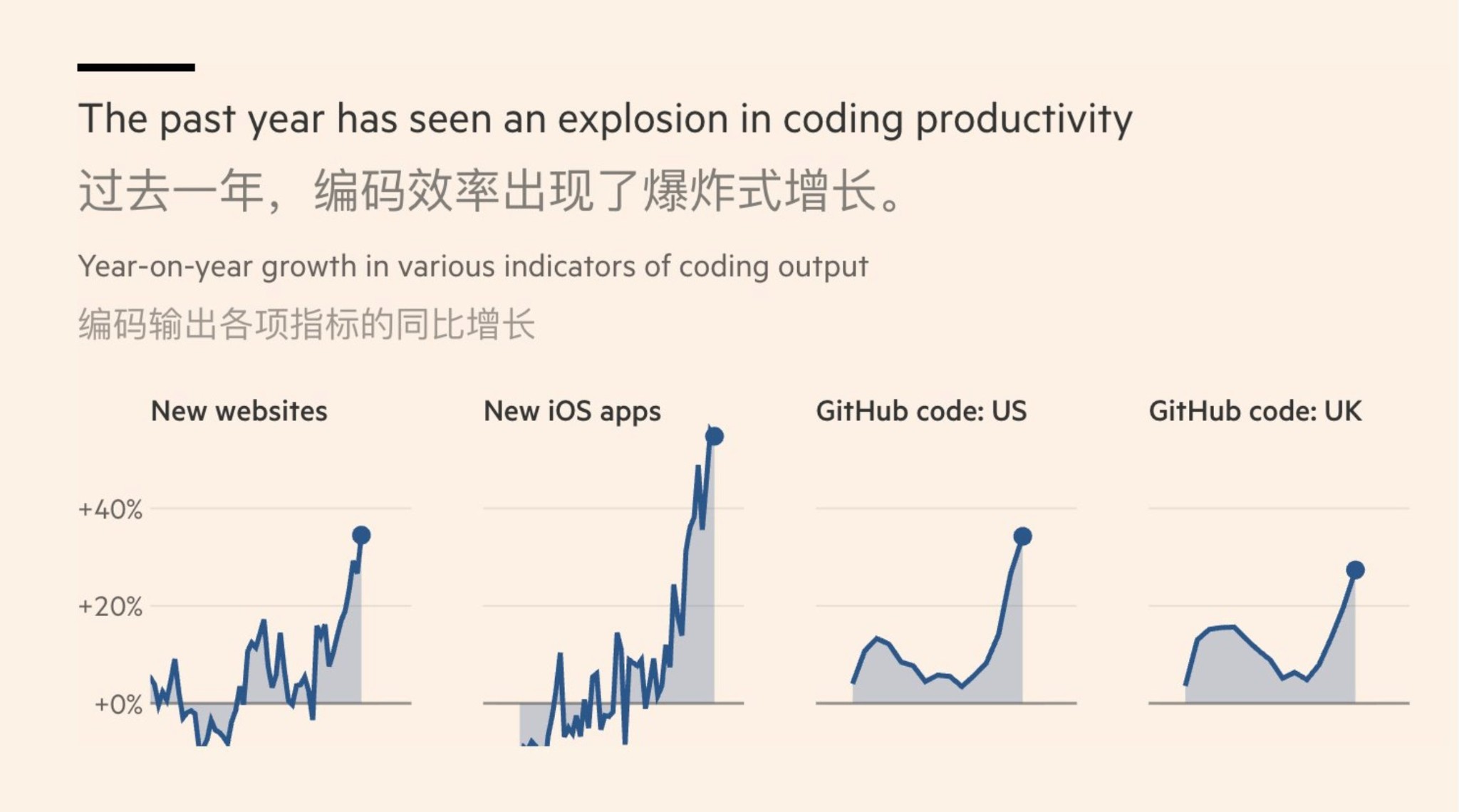
马斯克说了,今年年底就不用再写程序了,AI会直接生成最优的二进制代码。我最害怕的事情还是发生了。两年前我就担心这件事,说AI编程一旦玩起端到端来,那人类就彻底没有什么事情了。虽然现在编程我们也不需要去看代码了,或者说通常不太需要去看代码,但是那个代码还是可以读的。代码我们还是可以进去看看到底有什么问题的,但一旦变成端到端了,就变成0101了,这玩意你就彻底没法看了。
很多不懂编程的人都很嗨,他们以为程序都是通过二进制代码在跑的,其实压根不是这么回事。还好这是马斯克说的,他说的东西未必什么时候能够实现,但是让我担心的是,马斯克说的东西很多还真的实现了。
今天这个故事分三段来讲:
- 第一段,马斯克在什么样的会上说的这个事?在 xAI All-Hands大会上说的这个事情。
- 第二个,编程真的会变成端到端吗?在这个过程中到底有哪些难点需要克服?
- 第三个,xAI还会剩下4个部门,他们未来会向什么方向走?
xAI All-Hands大会:公开的“闭门会议”与正视听

首先咱们先讲一点,xAI All-Hands大会(所有的手都在),这个是一次被公开的闭门会议。本来应该是大家关起门来开,1000多人塞在一个屋里开会,有全程录像。但是2月11号开完了以后,40多分钟的视频就全都放出来了,所以这个会其实是开给公众看的。为什么开这样的一个会?xAI最近有大批的员工离职了,必须要以正视听,否则的话会全面崩盘的。一堆人离职了以后,剩下的人就会人心惶惶:你这事还干不干?是不是没得干了?