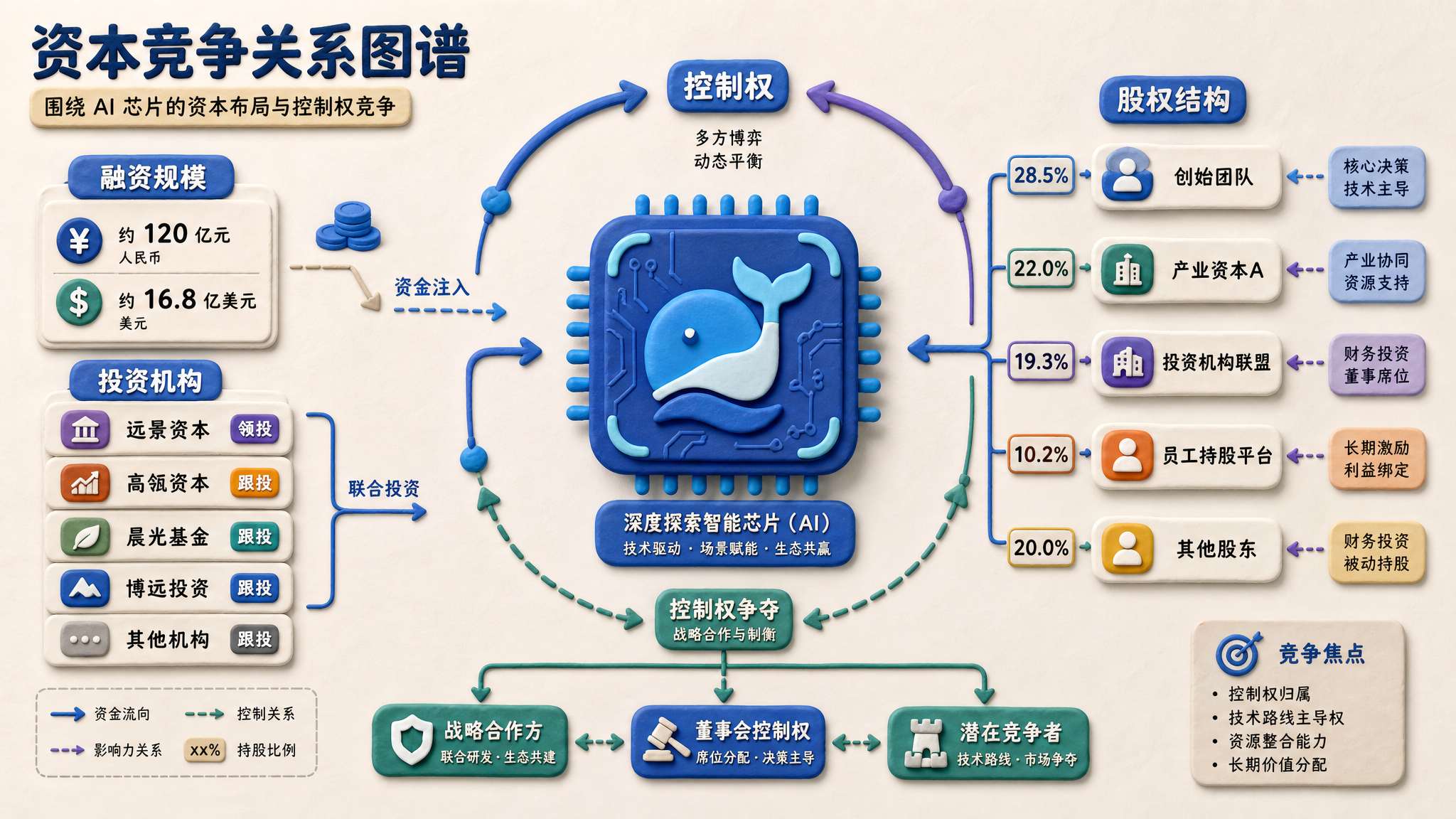
DeepSeek 510亿元人民币融资落地,梁文锋如何通过四条条款战胜资本?
大家好,欢迎收听老范讲故事的 YouTube 频道。
首先确认一个数字,不是500亿,而是510亿。这个数据待会儿咱们仔细拆分一下。这是中国 AI 公司有史以来最大的一笔单笔融资了,而且因为 DeepSeek 这是它的第一次融资,所以也非常受人瞩目。
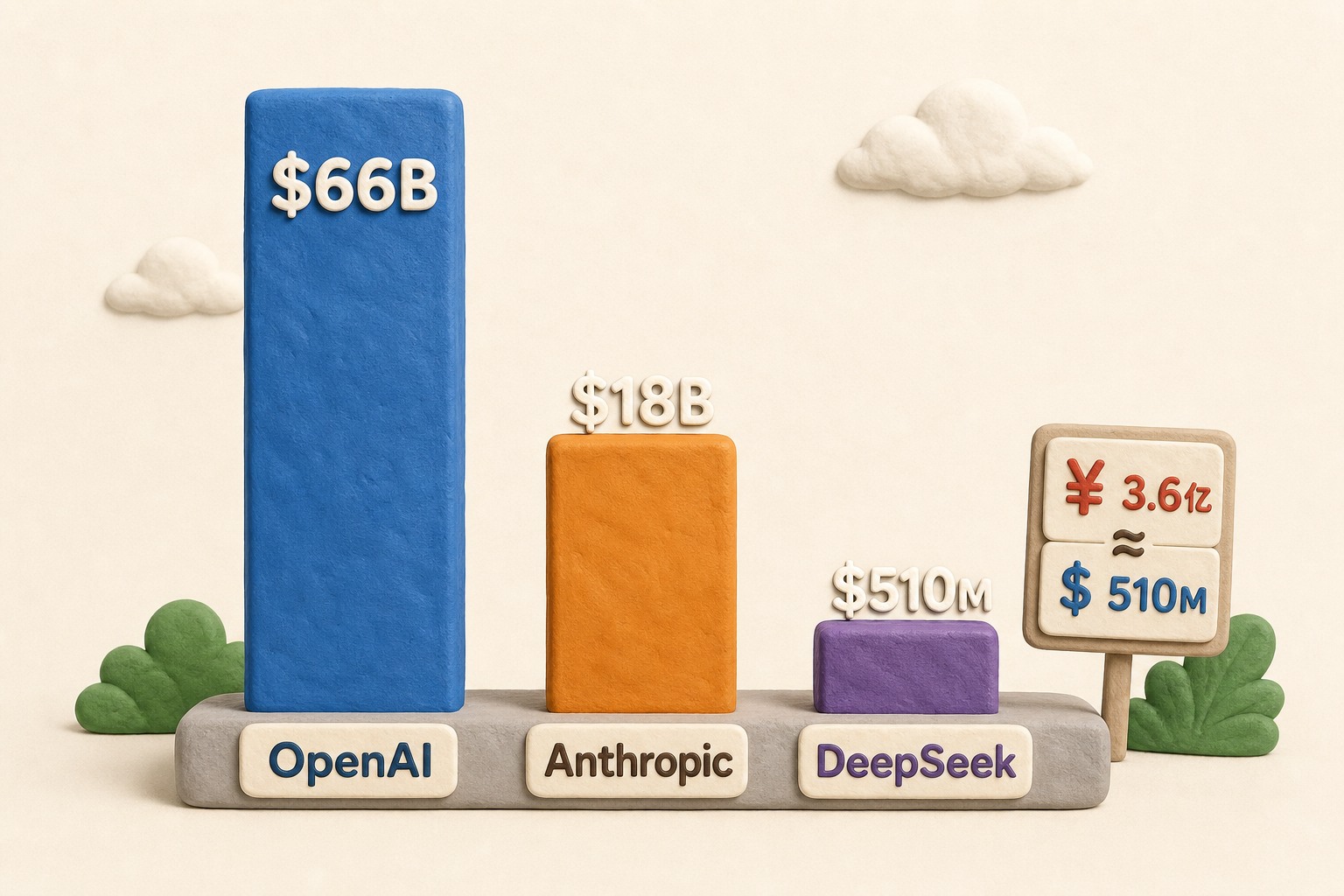
中国的 AI 公司融资,我们总是要跟美国比一比。我们在模型上追赶,融资上是不是也在追赶呢?这个距离好像稍微差得有那么一点点远。
- Anthropic 总共融了1,163亿美金,不是人民币,是美金。
- OpenAI 总共融了1,500亿美金。
- DeepSeek 这是第一轮,累计融资510亿人民币,大概相当于74亿美金。
所以 DeepSeek 的融资额是 Anthropic 的1/15.7,是 OpenAI 的1/20。
中国确实吃苦耐劳,确实比较省钱。中国绝大部分的 AI 公司里头,用的人肯定是要比美国人便宜,不是说我们人差,只是我们薪资低而已。另外,我们也确确实实没有那么多算力卡,也没有烧掉那么多电费。所以在这一块上,我们要比他们省钱很多。
但是同样一个事情,要看跟谁比。你去跟 OpenAI、Anthropic 比,我们这个融资确实是非常非常小。但是如果去跟国内这些 AI 公司比,那么 DeepSeek 这个510亿人民币,就是有史以来最大的单轮。