

马斯克的年度访谈:乐观主义与即将到来的丰饶时代
大家好,欢迎收听老范讲故事的YouTube频道。埃隆·马斯克这一次都讲了什么样的金句出来?
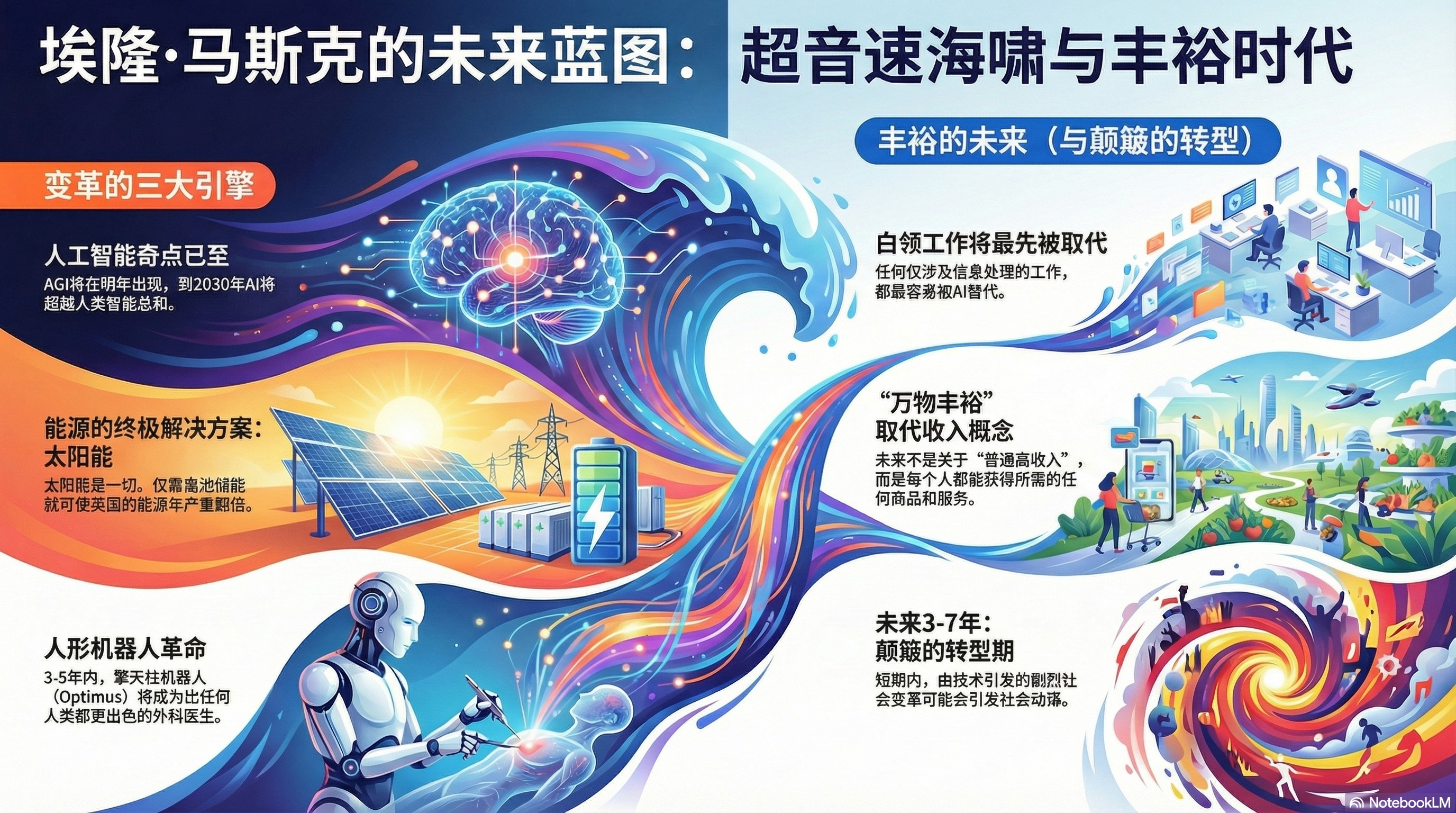
- “我们正走向全民高收入”;
- “你可以拥有任何你想要的东西”;
- “不要为10年或20年后的退休而存钱,那已经没有意义了”;
- “未来的货币本质就是瓦特功率的单位,未来能源就是货币”;
- “去读医学院已经没有意义了,擎天柱三四年内就可以超越优秀人类医生的外科手术水平”;
- “你是被程序设定为会死亡的,如果你改变这个程序,你就会活得更久”;
- “太阳就是一切,相比于太阳,其他所有能源都像是原始人在往火里扔树枝”;
- “中国在AI算力方面将远超世界其他地区,中国似乎听取了我所说的一切并付诸行动了”。
这就是马斯克这一次讲的一些金句。
访谈背景

这一次访谈的背景是什么?它是X上以及YouTube上的一个频道叫Moonshot(登月频道),他们做的一次访谈。彼得·戴曼迪斯以及戴夫·布隆登他们两个采访的马斯克。位置是在德克萨斯州奥斯汀面积达到1,150万平方英尺的特斯拉超级工厂里面,这个工厂是生产Cybertruck和Model Y的。时间是2025年的12月22日。
这是第一次,这个Moonshot频道已经跟马斯克约好了,以后每年的12月22日都会来做访谈,所以这是一个年度访谈,这是第一回。访谈时长接近3个小时,先在X平台上播放——毕竟马斯克的访谈嘛,你不先在X上播放,这事马斯克肯定是不乐意的——然后转到了YouTube平台上。如果有兴趣可以自己去看,访谈视频经过了精心的剪辑,主题就是“乐观主义与即将到来的丰饶时代”。
访谈的内容跳跃性极强,因为马斯克自己的思维就是跳跃性极强的,所以你如果直接去听访谈的话,会显得稍微有一点点凌乱。那么老范就给大家总结一下吧。