 RSS
RSS怒喷大模型连狗都不如?揭秘硅谷集体幻觉与物理常识缺失,为何只有新架构才能通往通用人工智能|Yann LeCun World Models AMI LLMs AI Startup
12 月 23
AIGC Abstract World Models, Advanced Machine Intelligence, AGI, AI Startup, AI创业, AI未来, AMI, Autonomous Driving, Deep Learning Limitations, Dog Intelligence, Future of AI, Intelligent Agents, JEPA, LLM Dead End, LLMs, Meta AI, Minimum Cost, Open Source AI, Physical AI, Physics & Planning, Robotics, Safety Alignment, Spatial Intelligence, System 2 Reasoning, World Models, Yann LeCun, 世界模型, 大模型死胡同, 大语言模型, 开源AI, 抽象世界模型, 智能体, 最小消耗, 机器人技术, 杨乐坤, 深度学习局限, 物理AI, 物理与规划, 狗的智能, 空间智能, 系统2推理, 联合嵌入预测架构, 自动驾驶, 通用人工智能 怒喷大模型连狗都不如?揭秘硅谷集体幻觉与物理常识缺失,为何只有新架构才能通往通用人工智能|Yann LeCun World Models AMI LLMs AI Startup已关闭评论

杨乐坤“暴论”:大语言模型是扯淡,连狗都不如?解读他的世界模型与新创业项目AMI
“我认为这完全是扯淡,这条路根本就不可能成功。”这是杨乐坤在最新的访谈中对大语言模型路线的评价。这是语不惊人死不休的这种暴论吗?还是说他真的有一些什么事情想做?
大家好,欢迎收听老范讲故事的YouTube频道。
12月15日,杨乐坤发布了他最新的访谈。访谈是在一个叫做“信息瓶颈”的播客中进行的,位置应该是在纽约大学。杨乐坤当时还在Meta站好最后一班岗,三周以后会正式离职。访谈接近两个小时,我尽量讲一些里边有意思的部分。
现在的大语言模型还无法跟狗的智能相比,这个也是其中比较有趣的一点。到底杨乐坤想做的世界模型,以及他的JEPA是如何工作的?对于我这个讲述者和各位听众来说,都是一个挑战。请耐心听到最后,然后告诉我,我到底讲明白了没有?你们到底听懂了没有?杨乐坤要去做的AMI,也就是创业要做的这个新公司,到底是干什么的?怎么挣钱?咱们今天就讲这几块。
第一块:杨乐坤为什么觉得大语言模型完全是扯淡?

这里头要讲到的最核心的观点叫“序列化”。大语言模型工作的方式,是把整个世界的这些语言进行序列化。所谓序列化是什么?就是把所有的语言变成TOKEN,然后把这些TOKEN离散掉,谁跟谁之间都没有关系,再通过把全世界的语言搁在一起进行统计、进行训练,重新建立起这些TOKEN与TOKEN之间的关系。它是这样来工作的。
而且要注意一点,语言这个东西本身就是一个世界映射,语言只能表达世界中的很少一部分。哪怕是同样的语言,你用不同的语气语调来说,都会表达不同的意思。而不同的语气语调,你在语言中是完全无法看到的。所以语言只是真实世界的一个稀疏映射,大量的信息被错漏了。所以在TOKEN化的这个过程中,大语言模型其实把大量世界本身相关的信息都扔掉了,特别是那种连续的信息。
因为大语言模型通常能干的事是什么?就是预测下一个词应该说什么,哪个词是最好的。但是在这个过程中,它对于让世界演变这些连续事件,它是没有办法去进行预测的,因为它在序列化的过程中就把所有这些关联全扔了。
缺乏物理世界的关联与约束
大语言模型之所以可以回答问题,是因为以前有类似的文档。但是回答的时候,大语言模型并不知道这些内容之间的关联与约束。比如说问它:“我把这个杯子扔下去会怎么样?”它会根据过往的文档训练,给你回答说:“这个杯子会自由落体掉落,掉在地上会碎掉。”但是它不知道是因为有重力加速度、万有引力,因为这个玻璃很脆弱,掉在地上以后会摔碎。这些东西它是不知道的,只是因为以前有一些文档告诉你说这个杯子扔出去会摔碎,其他的它是不知道的,里头相关的约束以及这个关联都没有。
推理成本极其浪费
而推理成本是极其浪费的。咱们现在大语言模型,从OpenAI出O系列模型以后,都可以thinking了,都有COT(Chain of Thought)就是推理过程了。这个过程在杨乐坤看来,是极其极其浪费的。为什么?就是它不直接出结果,而是出中间的推理步骤,而且这些推理步骤是一次出一大堆,再由一个专家或者几个专家模型去进行筛选,在里头再挑一个能用的。说这个过程太浪费算力了,实在是没有必要。
安全缺失与事后补救

还有就是安全缺失。说现在的所有安全手段都是非常容易被越狱的,因为什么?你在训练的时候已经把所有的约束都去掉了。你说这个玻璃杯掉在地上会碎裂,这个事儿它是通过训练训进去的,但是它并没有说有一个基础的约束在里头。所以它在一大堆的训练以后,这个模型只能够去猜测下一个TOKEN出什么最合适。
你要想让它进行安全方面的对齐或者是约束,怎么办?你只能是说做事后微调,或者是设置外部围栏:你问了这些问题我就不回答了。事后微调就是我出了什么样的结果,我就如何去处理了;或者我出结果的时候我会进行筛选。这个本身是非常非常不安全的,因为你没有底层的一个逻辑。它是底层先生成一大堆不安全的东西以后,你再去进行后训练,再去进行围栏,这个是非常麻烦的。
还有一个就是成本很高。很多安全措施也是让大模型一次生成一堆结果,然后在里边挑一些相对来说比较安全的给你展示,说这个过程也很浪费。而且大模型是缺乏对于物理世界后果预测能力的。大模型能够预测的只有一件事,就是下一个词出什么最合适。它没法预测说“我这个动作做完了以后会有什么结果”,也缺乏规则的约束。那你说怎么能够判断安全?你一定是说我先预测一下我这个动作做了以后会怎么样,然后再去根据结果预测安全。大模型是没有这个能力的。
硅谷陷入了集体幻觉
第三个是硅谷现在陷入了集体幻觉。硅谷相信,我们只需要不断的去喂数据(包括后边的合成数据),进行人工的管教(也就是后期的微调和对齐),进行技巧的堆砌(也就是强化学习),你就可以不断的让大模型学会新技能。硅谷的AI已经被单一文化所绑架了,大家都怕其他的尝试会落后,只敢低头拉车,不敢抬头看路了。明明有很多其他的方向,我们就不试了,这就是唯一方向,我们就往前走了,这个是非常非常危险的。
所以总结一下,杨乐坤认为大语言模型就是扯淡的三个原因:
- 第一个原因是序列化,就这东西从一开始它就不对,你就丢弃了大量的信息,而且是打破了所有的关联和约束以后重新训练出来的;
- 第二个就是很不安全;
- 第三个就是硅谷整个陷入集体幻觉了,对其他的所有可能性都拒绝尝试了。
第二块:杨乐坤为什么认为现在的大语言模型还无法达到狗的智能?

我们很多人已经因为大语言模型都失业了,它都已经开始替代人的工作了。现在我们一看这玩意连狗都不如,被替代工作失业的人是不是觉得很冤?其实原因也很简单:狗是没有语言的,它并不会去描述这个世界是怎么样、我要去做什么,但是狗依然可以在物理世界中很好的生存,而大语言模型是不具备这个能力的。
狗的世界模型它会记住什么?物体不会凭空的出现与消失。这里有一个杯子,扭过头去再扭回来,这个杯子应该还在。这就属于最基本的物理约束。在我们训练大语言模型的时候,再把这些语言信息进行符号化的时候,进行TOKEN化的时候,这些东西就都丢了。所以狗是有这些底层约束的,而大语言模型没有。
再加上比如说运动力和惯性这些基础的东西,这些玩意不需要牛顿出来,这个狗也知道。它不需要学习,不需要去考试它也知道。说“我跳起来不会马上掉下来,我跳起来会顺着这个惯性接着往前跑一段”,这些东西狗是天生就知道的,或者说它可能生下来经过简单的学习就可以知道。
而且狗是有视觉、听觉、嗅觉和触觉的,可以接收这些信息,可以判断这是什么的味道、这是在哪个方向上、这个东西距离我有多远。这些东西很多都是没有办法通过语言去进行描述的,但是狗可以在这些基础约束下在物理世界中进行活动,而且还活的很开心。狗是可以进行规划的,它要去规划一下我要去怎么抓住老鼠(狗拿耗子这个没关系了,反正甭管抓什么吧),它要去抓一个东西,它可以预测可能的结果,并且做出选择并得以生存。这就是狗真正强的地方。现在大语言模型还做不到这些东西。
大语言模型只能输出语言,而语言仅仅是现实世界一个很小的投影以及很疏离的映射。真实世界中的大量的信息都没有映射到语言上去,所以大语言模型到现在为止还不如狗。等哪天新的世界模型可以像狗一样聪明了以后,咱们再继续往前走。
所以杨乐坤认为,说现在大语言模型这条路是永远不可能超越人的。因为人虽然我们现在在这呱啦呱啦说话,你们也在这听我说话,但是我们离开语言是依然可以在物理世界中生存的。可能未必有狗活的舒服,但是我们也可以在物理世界中,也可以在现实世界中生存。所以在把这些物理世界的基本约束丢掉以后,大语言模型永远也不可能超越人类。
第三块:杨乐坤的抽象世界模型(JEPA)到底想干点什么?
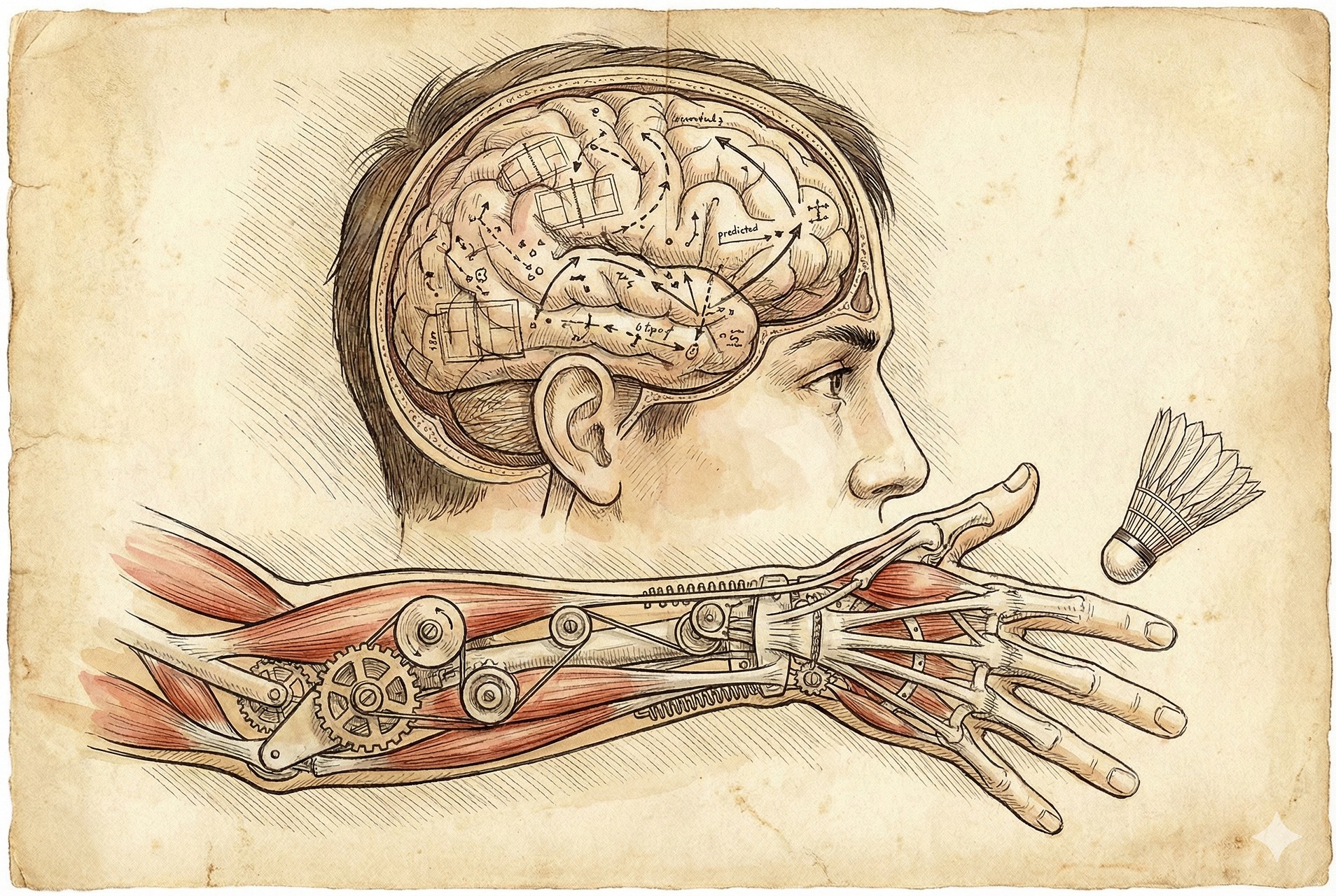
这是对我们的考验,我尝试把它说清楚,也希望大家能把它听明白。首先,杨乐坤的抽象世界模型里头有四个要素:抽象、分层、预测、最小消耗。就是这四个要素组成的整个这个系统。
1. 抽象 (Abstraction)
所谓抽象就是不去预测每一个像素,那太浪费了。你不可能说我预测出这个视频的下一帧来,这个事是不行的。只记录基础的知识,预测大致的结果就OK了,这是他现在要去做的事情。
比如说吧,咱们打羽毛球,当对面那个球打过来的时候,我们会去判断球的轨迹,做出动作击球,但是并不会计算所有的细节,也没有办法去想象在我们击球过程中每一帧画面的所有像素,但是我们依然可以开开心心的在球场上打球。这就是抽象的一个魅力。而且这些基础知识甚至还不是说通过物理的方式我去学、通过数学的方式我去学,公式怎么做、抛物线怎么算、风阻怎么来、这个速度什么,不是这样。我们只是说通过一些习惯,他这样打过来以后,我应该怎么去接,他是这样来去训练出来的。很多的羽毛球冠军,我估计他们的数学跟物理也未必能考及格,但是人家依然是羽毛球冠军。这个是他要去做的第一件事,叫抽象。
2. 分层 (Layering)
抽象之后下一步就是分层。所谓分层,他现在使用的这套系统叫JEPA,叫“联合嵌入预测架构”。什么意思?咱们依然以打羽毛球为例。
- 高层的预测:我们首先对高层数据嵌入进行预测。高层是我想着我应该回一个什么样的球,我是要回一个后场的高球,还是前场的吊球,还是做一个假动作,这个就属于高层次的思考。
- 低层次的预测:我这个手脚应该怎么动,怎么协调,我这个手腕应该怎么去摆,怎么去发力,这就是低层次的。
所以他就是在不同的层次想不同的事情。其实我们人去做很多的这种决策或者动作的时候,也是这么去思考问题的。如果你在高层去想这些低层的问题,不是想说我要怎么去给你发一个后场的高调球,而是想着我应该怎么去发力、我应该怎么去动手腕,那一定会出问题的。
3. 预测 (Prediction)
这个预测是什么?就是在世界模型中预测做出相应动作之后的结果。杨乐坤还是会去训练一个世界模型的,里边有一些刚才我们讲的物理公式、数学公式、一些基本的约束,把这些东西训练到物理模型里、世界模型里去。
你说我根据前面的分层的这个方式,我去进行预测了。比如说吧,在我们看到球过来的时候,就会去预测我们把这球打回去以后有几种不同的可能性:我回一个后场球,对方有可能会到后场给我做一个跳杀,或者在后场再给我回一个前场球,或者在后场再给我去回一个后场球,他有几种可能性。我们要去判断,我们把这个可能的结果进行推测。甚至有可能说,我这一个球杀不死他,但是我把他调到后场去,他可能步伐会混乱,再回一个球就有可能回的质量不是那么高,可能给我回一个前场高球,我就可以在前场扣杀他了。我会要做这样的判断或者是一些预测,或者叫规划吧。有的时候我们的这种预测和规划会分成很多步,然后才能去做决策。
4. 最小消耗 (Minimum Cost)
那决策下一步是什么?叫最小消耗。这就是我们决策的过程。你看我们已经抽象了,也分层做了思考了,然后做了预测了,在世界模型下给预测的结果都给我了。下一个事我要选择,这么多的预测结果里我选哪一个?怎么选?它有一个消耗函数,叫cost的一个函数。
什么叫最小消耗?就是你这样回最容易获得胜利,消耗最小的体力,让你觉得最舒服,不适感最低。你要做这样的一个选择,实际上就是计算一个最优解出来。预测之后在不同的结果中选择消耗最小的那个去执行。
安全与结构化

所有的安全约束都可以在这去计算。如果你说我现在把球打出去以后,它有可能会出界,这就是一个安全约束了嘛。这就属于一个消耗很大的一个因素在里头,那么我们就不要选择这样的一个结果,我们要选择其他的动作去做。这就是最小消耗。
它的安全也是在刚才我们讲计算最小消耗的时候就可以直接计算进去了,所以它是一个结构化的安全方案,将安全直接写到底层的硬代码里头去,通过优化实现安全。也就是先模拟,确保满足所有的安全约束,才进行执行。我模拟了以后,你这个安全约束一旦违反了以后,你的消耗函数就会给你返回一个巨大的值,这个选项就直接过滤掉了。它是通过这样的方式来保证安全的,是很难越狱的。
工作流程总结
- 首先我们要提出动作的序列,先要有一个计划;
- 然后在世界模型中进行模拟(当然这个模拟是分层去模拟,高层是什么样,底层是什么样的);
- 然后评估成本,找到最小消耗,也就是最小化不适感,让你这个动作做完了以后舒服;
- 根据这个评估的结果对这个动作进行优化,并且执行,作用于真实世界。
这就是这种世界模型的一个运作方式。
第四块:行业点评与未来展望
点评其他“世界模型”
杨乐坤对于现在行业中正在研究的各种号称是世界模型的项目是如何点评的?他说伊利尔的这个SSI(就是超级安全智能),现在完全搞不清在干嘛,可能已经成了一个笑话了。就是伊利尔自己也搞不明白在干嘛,他的投资人也搞不明白他在干什么,这个就没法整了。其他的有些点名了说这几个还不错,那几个不怎么样。但是李飞飞的世界实验室并没有被点名。
杨乐坤给出了评判的标准:什么样的是真世界模型,什么样的是错误道路(依然是在大语言模型的基础上继续狂奔的)。它的判断标准就是:所有生成式的、生成所有像素的,这种都跑歪了。而李飞飞的世界模型,包括OpenAI的Sora世界模型,都属于这一类。他们都属于是生成式的,要生成视频的,要生成所有像素的,这个事都是错的。只有在抽象世界中,基于基本原则去进行预测和规划,才是正确方向。
与大语言模型的关系

杨乐坤的世界模型与现在的大语言模型之间到底是什么关系?是不是要颠覆?倒也不是。他的预测是:未来世界模型负责底层逻辑,而大语言模型只负责语言的部分就可以了。
就像我们现在大脑里头,其中有一部分是只负责语言部分的,而且这一块很小,只发展了可能100万年,很短的一段时间。而大部分时间,这个动物的大脑都是在跟物理世界打交道的。我们人类也是先在物理世界里头去进行各种判断,然后再去用语言输出或者进行交流的。就像刚才我讲这个打羽毛球这个过程,如果你一边打羽毛球一边把所有的步骤和思想过程全都变成语言,你就打不着球了,这个人是反应不过来的。我们经常说“手比脑子快”,我还没想明白,我的一个习惯动作已经上去了。这个世界模型就是要去做这些事情,语言只是需要的时候我再进行描述。
第五块:AMI公司是干什么的,怎么挣钱?

最后咱们讲一下,杨乐坤准备创业的AMI公司到底是干什么的,以及怎么挣钱。他这个AMI叫“高级机器智能”,准备融资5亿欧元,估值30亿欧元。
为什么融欧元?因为他准备放在巴黎,总部在巴黎,在纽约设办公室,所以他要融欧元。那这5亿欧元里头,Meta是重要合作伙伴,但不是股东。至少在这一次他做访谈的时候说了,Meta不是股东。Meta是不是给钱这个事,还要等他这5亿欧元彻底融完了以后才能知道。目前在融资,但是没有披露融资的细节。
杨乐坤是董事长,并不是CEO,应该还是要再找一个年轻力壮的人去做CEO。杨乐坤也65了,虽然在这种顶级科学家里头不算特别老的吧,但是肯定体力也没有那么跟得上了。
逃离硅谷与开源研究
在巴黎设立总部、纽约设立办公室,原因就是要逃离硅谷,因为硅谷现在已经被单一思想给垄断了。其实欧洲人看美国人的方式,跟纽约看硅谷的方式,以及硅谷看中国的方式都是一样的。什么意思?大家都觉得我们是在做基础研究,对面那帮人是在做应用研究。欧洲人就觉得我们在做基础研究,美国人都在做应用研究。美国的像纽约、波士顿这些东海岸的人去看西海岸的硅谷,想的也是这样:东海岸我们在做基础研究(像什么哈佛这些人在做基础研究),西海岸的这些(像什么斯坦福、UC Berkeley、包括硅谷)你们都是在做应用。硅谷看中国也是这样的,说我们在做基础研究,你们中国人只管超过去做应用就完事了。大家都是这样的一个思路,所以现在杨乐坤说算咱们欧洲干去。
杨乐坤要求要做开放开源的研究。他说不公开发表就不是真正的研究,这就是他跟Meta最后闹掰的一个核心原因。他希望他的各种研究可以公开发表,而亚历山大·汪进去了以后说不行,你必须要经过我审核了以后才可以发表。所以一气之下老头跑了。
杨乐坤为什么要求必须要公开发表?
- 他说你如果不公开发表的话,就容易自欺欺人(估计讲的是Llama4)。这个事必须要通过同行评审,才可以确保研究方向的严谨性以及结果的可靠性,所以必须公开发表。
- 开源则是吸引顶尖头脑的最佳手段。很多研究成果转化成产品需要数年甚至数十年,允许研究人员发表论文并且开源他们的结果,可以提供及时的激励和成就感,所以还是要鼓励开源的。
- 开源是实现AI多样化的唯一途径。杨乐坤是反对垄断的,他在Meta做了12年,做出Llama大模型来就是为了反对谷歌和OpenAI的垄断。
- 开源也是促进文化多样性的一个手段。如果被垄断了,那就没有文化多样性了吧,只有开源了才有不同的大模型可以去玩耍。
- 开源也是商业与经济最好的一个结果,可以在商业和经济上得到最好的回报。因为开源可以很好的赋能各种垂直领域,因为只有你开源了,别人才可以去这些垂直领域,才可以更方便的去跟你合作,可以最大化经济影响。
其实开源这里有一点杨乐坤并没有提,开源最大的好处是建立事实标准。因为一旦事实标准建立了,你整个这个系统就可以躺在那吃饭。现在英伟达的CUDA就是一个事实标准,虽然它并不开源,但它依然是一个事实标准,所有人都难以逾越。
商业模式
最后,AMI怎么挣钱?又是开放又是开源,我还要发表论文,我所有的产品我一开源了,别人就能用了,到底怎么去挣钱?现在他们的设想是,做好这个世界模型以后,为自动驾驶和机器人这些需要在物理世界中、需要在连续的时间序列中去做决策的这些企业,提供基础模型以及提供各种技术的支持和服务,通过这种方式去挣钱。
结语
最后总结一下今天的话题。对于我以及听众们都是一次考验,我希望我把杨乐坤的世界模型到底怎么做给大家讲明白了,或者让大家觉得我自己明白了也行。让我们尝试去理解杨乐坤的世界模型具体想做什么。期待杨乐坤在新的方向上依然可以做出有价值的贡献,不为短期经济利益所屈服,勇于尝试不同的方向,科技才可以进步。
好,这就是今天的内容,感谢大家收听。请帮忙点赞、点小铃铛,参加DISCORD讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
背景图片
Prompt:high-contrast watercolor painting, empty New York University computer lab interior, rows of sleek monitors and keyboards on long desks, ergonomic chairs pushed in, large windows with city lights filtering through, glossy reflections on screens and tabletops, neon cyan rimlight outlining equipment edges, deep navy background, sharp subject separation with extremely legible negative space for text overlay, minimal palette of ink blue neon cyan and subtle gold accents, cinematic composition, ultra-detailed, intricate linework, –ar 16:9 –raw –s 250 –v 7.0 –p lh4so59




